Virtualizing Big Data in the Cloud
I’m in sunny Phoenix this week at the Data Platforms 2017 Conference and looking forward to a break in the heat when I return to Colorado this evening.

As this event is for big data, I expected to present on how big data could benefit from virtualization, but was surprised to find that I didn’t have a lot of luck finding customers utilizing us for this reason, (yet). As I’ve discussed in previous presentations, I was aware of what a “swiss army knife” virtualization is, resolving numerous issues, across a myriad of environments, yet often unidentified.
The Use Case
To find my use case, I went out to the web and found a great article, “The Case for Flat Files in Big Data Projects“, by Time.com interactive graphics editor, Chris Wilson. The discussion surrounds the use of data created as part of ACA and used for another article, “How Much Money Does Your Doctor Get From Medical Companies“. The data in the interactive graphs that are part of the article is publicly available from cms.gov and the Chris discusses the challenges created by it and how they overcame it.

Upon reading it, there was a clear explanation of why Chris’ team did what they did to consume the data in a way that complimented their skill set. It resonated with anyone who works in any IT shop and how we end up with technical choices that we’re left to justify later on. While observing conversations at the conference this week, I lost count of how often I accepted the fact that there wasn’t a “hadoop” shop or a “hive” shop, but everyone had a group of varied solutions that resulted in their environment and if you didn’t have it, don’t count it out- Pig, Python, Kafka or others could show up tomorrow.
This results in a more open and accepting technical landscape, which I, a “legacy data store” technologist, was welcome. When I explained my upcoming talk and my experience, no one turned up their nose at any technology I admitted to having an interest in.
With the use case found online, was also the data. As part of the policies in the ACA, cms.gov site, (The Center for Medicare and Medicaid) you can get access to all of this valuable data and it can offer incredible insight into these valuable programs. The Time article only focuses on the payments to doctors from medical companies, but the data that is collected, separated out by area and then zipped up by year, is quite extensive, but as noted by a third article, as anticipated as the data was, it was cumbersome and difficult to use.
The Requirements
I proceeded to take this use case and imagine it as part of an agile environment, with this data as part of the pipeline to produce revenue by providing information to the consumer. What would be required and how could virtualization not only enhance what Chris Wilson’s team had built, but how could the entire pipeline benefit from Delphix’s “swiss army knife” approach?
- I can’t assume this is the main data store. These flat files are a supplement to legacy data stores.
- There would be a standard development environment- development and testing would need their own environments, not just a production copy of these files, applications, etc.
- If it’s providing data to a consumer and data is in perpetual motion in the age of the internet, an agile development method would need to be in place, which means a short development cycle with many, small, “scrum like” development groups from different departments working on tasks.
- Automation and seamless deployment would assist in less human intervention and resource demands, along with more successful deployments.
Solution
There were four areas that I focused to solve and eliminate bottlenecks that I either experienced or foresaw an organization experiencing when having this data as part of their environment.
- Eliminate the need to have multiple copies of the files, slow and manual process to propagate files to targets for development, test, etc. with Delphix’s vFile option, this would include any applications or other non-relational database tier included in the scenario.
- Eliminate any legacy data stores copies and refreshes that big data was dependent from and create VDBs for all development, test and reporting.
- Protect all non-production environments by masking non-production databases and flat files.
- Containerize environments for easy deployment, delivery, testing and cloud migrations.
vFiles
Each of the files, compressed were just over 500M and uncompressed, 15-18G. This took about over 4 minutes per file to transfer to a host and could add up to considerable space.
I used Delphix vFile to virtualize files. This means that there is a single, “gold copy” host of the files at the Delphix engine and then there’s an NFS Mount that “projects” the file access to each target, which can be used for unique copies to as many development, test and reporting copies.
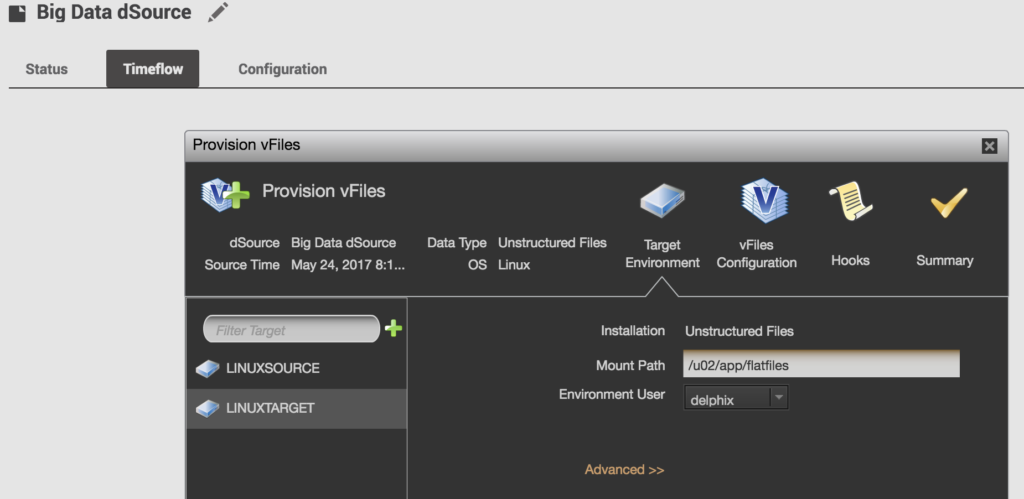
Fig. 1- Creating vFiles from dSource that flat files are sourced on.
If a refresh is required, then the parent is refreshed and an automated refresh to all the “children” can be performed. Changes can be made at the child level and if catastrophic, Delphix would allow for easy recovery, allowing for data version control, not just code version control throughout the development and testing process.
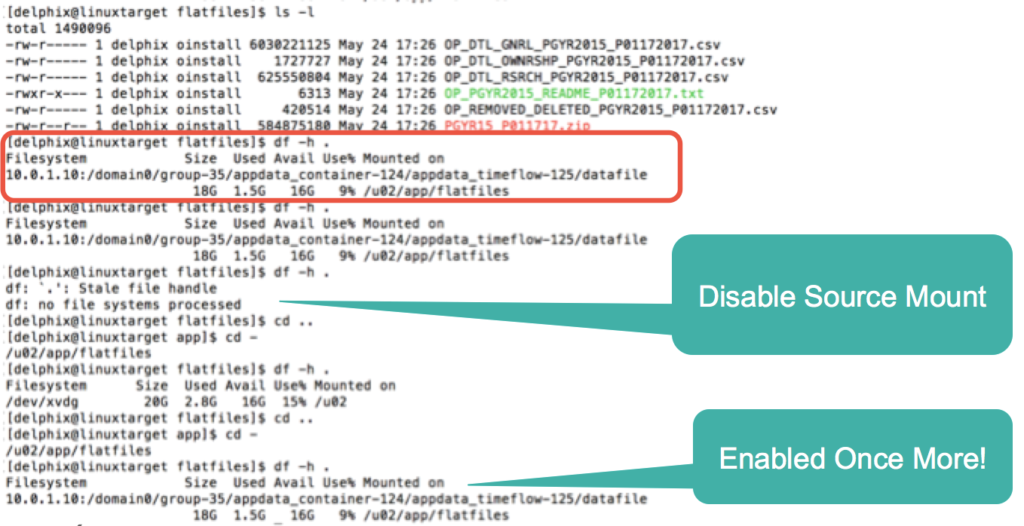
Fig. 2- Demonstration of target vFile, showing NFS Mount, files available, (created in less than 10 seconds) and how easily disabled and proven to be “Projection” of files.
Its a pretty cool feature and one that is very valuable to the big data arena. I heard countless stories of how often, due to lack of storage, data scientists and developers were taking subsets of data to test and then once to production, find out that their code wouldn’t complete or fail when presented against the full data. Having the ability to have the FULL files without taking up more space for multiple environments would be incredibly beneficial and shorten development cycles.
Virtualize
Most big data shops are still dependent on legacy data stores. These are legendary roadblocks due to their size, complexity and demands for refreshes. I proposed that those be virtualized so that each developer could have a copy and instant refresh without storage demands to again, ease development deadline pressures and allow for full access of data towards the development success.
Protect
Most people know we mask relational databases, but did you know we have Agile Data Masking for flat files? If these files are going to be pushed to non-production systems, especially with as much as we’re starting to hear about GDPR, (General Data Protection Regulations) from the EU in the US now, shouldn’t we mask outside of the database?
What kind of files can be masked?
- Multi-record
- CSV
- XML
- Word
- Excel
- PowerPoint
- Unstructured
- EDI
Thats a pretty considerable and cool list. The ability to go in and mask data from flat files is a HUGE benefit to big data folks. Many of them were looking at file security from the permissions and encryption level, so the ability to render the data benign to risk is a fantastic improvement.
Containerize
The last step is in simple recognition that big data is complex and consists of a ton of moving parts. To acknowledge how much is often home built, open source, consisting of legacy data stores, flat files, application and other dependent tiers, should be expected.
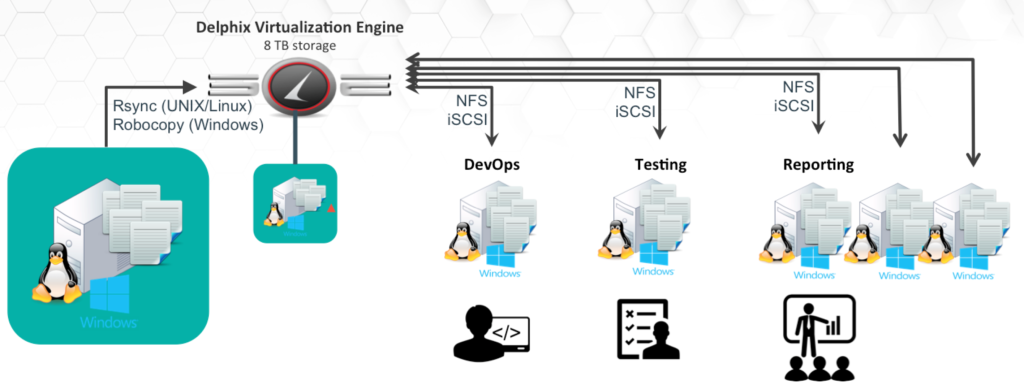
Fig. 3- A Container, created on-prem, then moved to the cloud and to as many environments as required for the development cycle to meet the business needs.
Delphix has the ability to create templates of our sources, (aka dSources) which is nothing more than creating a container. In my use case enhancement, I took all of these legacy data stores, applications, (including any Ajax code) flat files and then create a template from it for simple refreshes, deployments via jenkins, Chef jobs or other DevOps automation. The ability to then take these templates and deploy them to the cloud would make a migration from on-prem to the cloud a simpler process or from one cloud vendor to another.
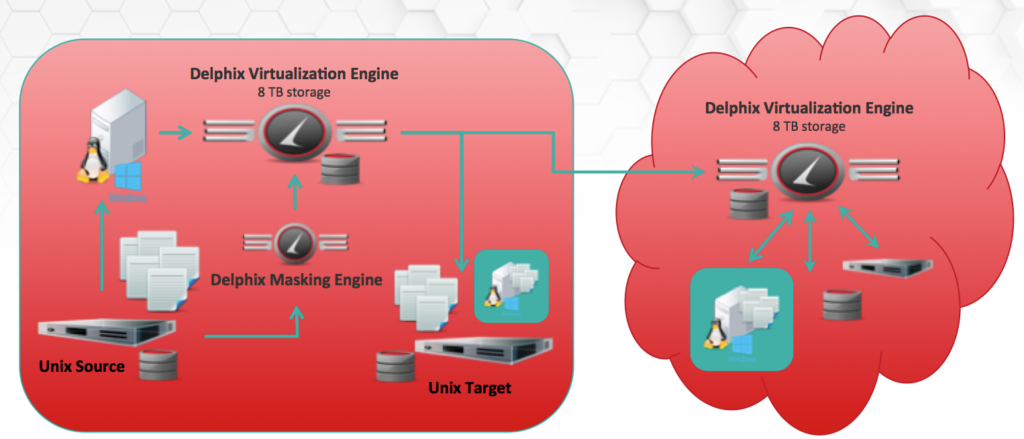
Fig. 4- A look at the full scenario- Delphix engines masking files, databases, creating containers and deploying it all on-prem and to the cloud.
The end story is that this use case could be any big data shop or start up in the world today. So many of these companies are hindered by data and Delphix virtualization could easily let their data move at the speed of business.
I want to thank Data Platforms 2017 and all the people who were so receptive of my talk. If you’d like access to the slide deck, it’s been uploaded to Slideshare. I had a great time in Phoenix and hope I can come back soon!