
AWR Warehouse in EM12c, Rel 4, Part II
So, there is a lot to cover on this topic and I hope Part I got you ready for more! Part II, I’m going to cover the following areas of the AWR Warehouse:
- Installation
- Access
- ETL Load Process
Installation
Let’s start with Prerequisites:
- The AWR Warehouse Repository must be version 11.2.0.4 or higher.
- The Targets and I think this will get a few folks, need to be 12.1.0.2 or higher, (now folks know why some docs aren’t available yet!:))
- Just as with installing ASH Analytics, etc., make sure your preferred credentials are set up for the database you plan to use for the AWR Warehouse repository.
- You should already have your database you plan on using for the AWR Warehouse repository discovered in your EM12c console.
- Any database targets you wish to add at the this time to the AWR Warehouse setup should also be pre-discovered.
- For a RAC target or AWR Warehouse, ensure you’ve set up a shared location for the ETL load files.
Now the repository is going to require enough space to receive anywhere from 4-10M per day in data, (on average…) and Oracle highly recommends that you don’t run anything else on the AWR Warehouse database, so don’t use your current EM12c repository database or your RMAN catalog, etc… Create a new repository database to do this work and manage the data.
To Install:
Click on Targets, Databases, which will take you to your list of databases. Click on the Performance drop down and choose AWR Warehouse. As no AWR Warehouse has been set up, it will take you promptly to the wizard to proceed with an initial workflow page.
Click on the Configure option and choose the database from your list of available databases to make your AWR Warehouse repository database. Notice that you next need to select Preferred Credentials for both the database target and the host it resides on. As the ETL process does perform host agent host commands, both these credentials are necessary.
Next page you’ll set up the retention period for your AWR Warehouse. You can set the value to number of years or choose to retain the data indefinitely for you data hoaders… 🙂 You can then set the interval to upload data, (how often it processes the ETL load…) which defaults at 24hrs, but you can set it as often as once per hour. Due to potential server load issues considering size of environment, # of targets, etc., I would recommend using the default.
Next set up the location for the ETL dump files. For RAC, this is where you will need to specify the shared location, otherwise, for non-RAC environments, the agent state directory will be default. I recommend setting up an exclusive directory for RAC and non-RAC targets/AWR Warehouse.
Click on Submit and monitor the progress of the deployment in the EM Job Activity. The job will be found quickly if you search for CAW_LOAD_SETUP_*.
Accessing the AWR Warehouse
Once set up, the AWR home can be accessed from the Targets menu, click on Databases, then once you’ve entered the Databases home, (databases should be listed or shown in a load map for this screen, click on Performance and AWR Warehouse.
The following dashboard will then appear:
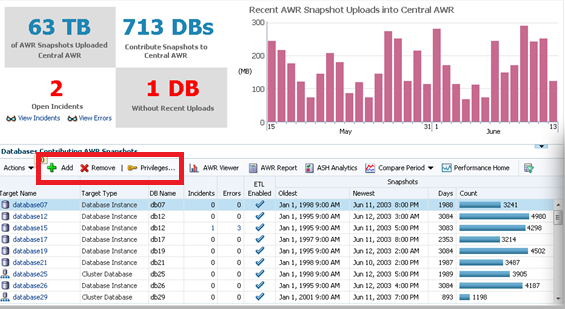
From this dashboard you can add or remove source targets and grant privileges to administrators to view the data in the AWR Warehouse.
You can also view the AWR data, run AWR reports, do ADDM Comparisons, ASH Analytics and even go to the Performance home for the source target highlighted in the list.
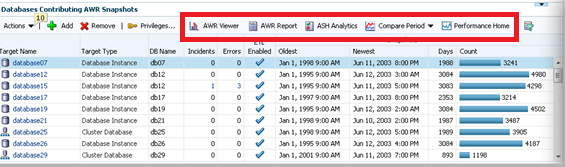
Note for each of the databases, you can easily see the Source target name, type, DB Name, (if not unique…) # of Incidents and Errors. You can see if the ETL load is currently enabled, the dates of the newest and oldest snapshots in the AWR Warehouse and the # of AWR snapshots that have been uploaded to the repository.
Now how does this all load in?
The AWR Warehouse ETL
The process is actually very interesting. Keep in mind. These are targets, source and destination, but what will drive the ETL job? How will the job be run on the targets and then to the destination AWR warehouse? Now I was sure the repository used TARGET_GUID to keep everything in order, but since the ETL does have to push this data from a source target through to the destination repository via the host, there is definite use of the DBID, too.
To upload the AWR snapshots from the target to the AWR warehouse, an extract is added with a DBMS job as part of a new collection on a regular interval. There is first a check to verify the snapshot hasn’t been added to the warehouse repeatedly and then the extract is identified by DBID to ensure unique info is extracted.
The second step in the ETL process is the EM12c step. Now we are onto the EM Job Service and it submits an EM Job on the host to transfer the data from the target to the warehouse host for the third part of the ETL process. This is an agent to agent host process to transfer the dump files directly from target host to AWR warehouse host, so at no time do these dump files end up on the EM12c host unless you were housing your warehouse on the same server as your EM12c environment.
The last step for the ETL process is to then complete the load to the AWR warehouse. This is another DBMS job that takes the dump files and imports them into the AWR Warehouse schema. DBID’s are mapped and any duplicates are handled, (not loaded to the final warehouse objects…)The ETL is able to handle multi-tenant data and at no time is there a concern then if more than one database has the same name.
Retention Period
Once the retention period has been reached for any AWR warehouse data, the data is purged via a separate job set up in EM12c at the time of creation, edited later on or set with the EM CLI command. A unique setting can be made for one source target from another in the AWR Warehouse, too. So let’s say, you only want to keep three months of one database, but 2 years of another, that is an option.
For Part III, I’ll start digging into more specifics and features of the AWR Warehouse, but that’s all for now!
Pingback: 12.1.0.4 is HERE!! – PeteWhoDidNotTweet
Thanks for the great article, do have a question around cloning. What happens when a database is cloned? For example a non production database is sending AWR data to the warehouse. Since it is non prod it is refreshed from production a weekly database. With a new DBID generate on each RMAN duplicate does that mean I can’t compare AWR data across RMAN clones? After cloning does the ETL process need to be setup again for the non prod database?
This looks like a really interesting new feature! I’m a little disappointed that they don’t support 11.2.0.3, but it looks really cool and definitely something that’s been needed for a long time!
-Jeremy
Pingback: AWR Warehouse in EM12c, Rel 4, Part II - Oracle - Oracle - Toad World
Hello Kellyn,
@ Click on Targets, Databases, which will take you to your list of databases.
@ Click on the Performance drop down and choose AWR Warehouse.
@ As no AWR Warehouse has been set up, it will take you promptly to the wizard to proceed with an initial workflow page.
I did a fresh install of OEM 12.1.0.4 today.
Username->About Enterprise Manager shows: Version 12.1.0.4.0
Targets->Databases->Performance contains next entries:
SQL Performance Analyzer
Run SQL…
Database Replay
No AWR Warehouse 🙁
Same for SYSMAN user.
I have many discovered databases, versions: 11.2.0.3, 12.1.0.1.
Searched MOS Community.
Found topic with probably same issue: https://community.oracle.com/message/12507512#12507512
I carefully read prerequisite section:
@ The AWR Warehouse Repository must be version 11.2.0.4 or higher.
@ The Targets and I think this will get a few folks, need to be 12.1.0.2 or higher, (now folks know why some docs aren’t available yet!:))
I’m in doubt.
AWR Warehouse entry will appear only when I install 12.1.0.2? 🙂
Thanks.
Best regards,
Mikhail Velikikh.
Pingback: Configuring AWR Warehouse (AWRW) in EM12c | Pardy DBA
Hi Kellyn
I configured AWR WH and added 2 DBs, one (Clod repository) is on same host and one is on different host in test environment.
After successfully creating dmp files both transferAWR processes always fail with:
Credential not found guid {0}
13:42:08 [ERROR] checkDumpSpace: aborting, error in reading warehouse credentials
I set predefined credentials for all three DBs (sys) and both hosts (oracle on cloud server and agoracle on test DB server).
Best regards from Slovenia
Igor
Good Morning Igor,
It sounds like you have the database credentials set up, but I’m a bit concerned that you are using the SYS account. The “checkDumpSpace error sounds like it could be a privilege issue to write to the OS level location and I don’t see host credential information. Please see the following support doc to assist in setting it up: http://docs.oracle.com/cd/E24628_01/server.121/e55047/tdppt_awr_warehouse.htm#CACDAGDG
Thank you and let me know if you need anything else,
Kellyn
It’s Morning for you 🙂
I was started with SYS to check if all is working as need and later I’ll use my DBA account. As our environment is very close to PCI DSS I hit many times to some undocumented “challenge”.
I will read support doc tomorrow as here it is 5 p.m.
Where I can find where to focus where and how transferAWR process is running? Any way to debug it?
Thank you for your attention
Igor
Definitely look in the dump directory you chose for you AWR setup for the source database to ensure that 1. the file is created. Also look to see if there is anymore info in the dbms_scheduler_job_details
Thanks,
Kellyn
Hi Kellyn
Dmp files (with logs) are on …/agent_inst directories on both hosts (for one DB on the same host as AWR_WHDB and for one test DB on different host)
In both gcagent.log I found:
..cut..
Dispatching request: PerformStreamedOperationRequest
..cut..
Reporting response: PerformStreamedOperationResponse (exitCode:0 output:null error:null) (request id 1)
I checked script transfer_awr.pl and I could not found ZIP files which should be done from dmp files.
Thanks,
Igor
Have you added the is level preferences credentials?
Please confirm.
Thanks,
Kellyn
List of my preferred credentials:
2 Default Preferred Credentials
SYSDBA Database Credentials (sys)
Database Host Credentials (agoracle)
and
2 Target Preferred Credentials
DB_awr – Database Host Credentials (oracle)
DB_oragrid – Database Host Credentials (oracle)
SYS pwd are same on both DBs and OS users are different on CLOUD/AWR server and test DB server.
Thanks,
Igor
Hi Kellyn
I removed both DBs from AWR WH, cleared all dump and log files, set all preferred credentials (agents, hosts, instances…) again, restart agents and error is still same.
Best regards
Igor
Hi Igor,
I’ve asked a number of our folks here who work with the product and no one has run into this issue. They recommend you open an SR, as they feel it’s a problem with the share that you are writing to.
Thanks and good luck!
Kellyn
Hi Kellyn
Thank you again for your time.
I will open SR and hope 🙂
Best regards
Igor
Hi Kellyn
I was sick and was lying in bad for 10 days.
I did not open SR but I’ve started from scratch and found some issues:
– ORA-47401: Realm violation for CREATE PACKAGE on DBSNMP.MGMT_CAW_EXTRACT (We are using DB Valult)
– ORA-01536: space quota exceeded for tablespace ‘SYSAUX’ (user DBSNMP without RESOURCE privilage)
– ORA-27040: file create error, unable to create file (different OS users for RDBMS, listener and agent)
– Connection failed: ORA-12170: TNS:Connect timeout occurred (no port open in FW between AWR and test DB)
As I wrote, we set our environment on PCI DSS (>90%) and using AWR WH is not just plug and play.
I hope my findings will help someone.
Best regards
Igor
Good Morning Igor,
Sorry to hear you aren’t feeling well. I hate cold and flu season- so many are feeling the brunt of it this year and I hope you are feeling better soon.. 🙁
I believe you have answered all your own questions here, but this isn’t a plug-n-play issue, this is an environment configuration issue that I don’t feel is rightly attributed to AWR Warehouse.
1. DB Vault configuration that is impacting the MGMT_CAW_EXTRACT pkg creation can be overcome.
2. You are missing a resource privilege to the DBSNMP user. This is easy enough to correct.
3. There is a firewall port block that is impacting your ability to perform successful file transfers across your network. That can be corrected and is not that uncommon in highly secure networks.
Thank you and good luck!
Kellyn
I’m fine, thank you.
Yes I have to dig into logs to discover what and how to set.
One question more:
When is planing that Cloud control will be able to use TCPS?
Best regards from Slovenia
Igor
Two questions about the AWR warehouse.
1. Can EM12c handle multiple AWR Warehouses for different targets? We have a
centralized EM12c setup (outside of our group_ but we want to house AWR for only the databases our group is responsible for, not the entire company.
2. Is the AWR Warehouse information essentially a full copy of the WRM/WRH tables in the source database per day or is it a subset of the data similiar to what would show on an AWR report? I don’t want to be able to just see the top sql oracle defines in the AWR reports but be able to drill into the data stored in the tables much more than what a report would show.
1. Each EM12c can have it’s own AWR Warehouse, with a designated AWR Warehouse repository database assigned to each. You would NOT want to have one database used for both, as it could result in conflicts.
2. It is a full copy of all the WRM/WRH objects, but it has added partitioning to offer better performance over extended retention. The partitioning is done on DB_ID, SNAP_ID and combinations of both. If you look at my slides or my advanced usage with it, you will see how you just need to add the dbsnmp.caw_dbid_mapping table to your queries to make them AWR Warehouse compliant.
Thanks,
Kellyn
Thanks for the information Kellyn. However for a little more clarity regarding #1. Can I have more than 1 AWR warehouse per EM12C? I would like to point some databases to one warehouse and some to another warehouse. Is that possible?
Hello Brian,
No, only one AWR Warehouse can be configured per one EM12c. This simply hasn’t been a requirement in the design and the ETL requires the configuration via cloud control, so one wizard configuration and the wizard will not come up again unless the existing AWR Warehouse has been removed. If this is done, the ETL step for agent to agent push from the source dbs to the original AWR Warehouse will no longer function.
Thanks,
Kellyn
Hi Kellyn,
I have configured Standalone db as AWR-Repository db. And i have added the RAC targets into the awr ware house. For some reason, Performance option is diabled on those targets. I have already raised SR, its in progress. Could you pls adivce , any workaround.?
Also, have you configured RAC database in your awr-warehouse, if so are you able to see performance option on those cluster databases?
Any suggestion will be helpful.
Thanks
Regards
Krishnan
Hi Kellyn,
I have configured Standalone db as AWR-Repository db. And i have added the RAC targets into the awr ware house. For some reason, Performance option is diabled on those targets. I have already raised SR, its in progress. Could you pls adivce , any workaround.?
Also, have you configured RAC database in your awr-warehouse, if so are you able to see performance option on those cluster databases?
Any suggestion will be helpful.
Thanks
Regards
Krishnan
Hi Krishnan,
Could you please check the optimizer level parameter for the databases in question? Is the value set to BASIC?
Thank you,
Kellyn
Using the default value.
optimizer_mode ALL_ROWS
How about STATISTICS_LEVEL? Apologies, I needed to know about STATISTICS_LEVEL and if it’s set to BASIC in the databases.
Thanks,
Kellyn
[image: Kellyn Pot’Vin on about.me]
Kellyn Pot’Vin-Gorman
about.me/dbakevlar
Thank you for your reply.
Both repository database and target databases are in “TYPICAL” .
STATISTICS_LEVEL =TYPICAL
This may be a silly question, but do you have the tuning and diagnostic packs licensed on these databases?
Yes , I have licensed for those datbases.
Another question now. I just created a new 12C EM on Linux 7 and when I go to Targets->Databases the only options I see under Performance are Sql Performance Analyzer, Run SQL and Database Replay. There is not an AWR warehouse option. I’m logged into OEM as SYSMAN. What am I missing please?
Look at the version of the EM12c, (should be 12.1.0.4 with the patch unless just downloaded… Ensure you have the patch for the AWRWarehouse included.
I did just download it within the last week.
./emctl getversion oms
Oracle Enterprise Manager Cloud Control 12c Release 4
Copyright (c) 1996, 2014 Oracle Corporation. All rights reserved.
Enterprise Manager 12c OMS Version 12.1.0.4.0
I’ll have to look for an AWR Warehouse patch. If you have the # can you let me know it please? I’ll look around though.
Try Master Note: Support note 1907335.1
yes, I have licensed on those databases
Hi Krishnan,
I’m not sure why you can’t see the performance options and would highly recommend opening an SR to get support from Oracle on this one.
Thanks,
Kellyn
Kellyn:
I was reading your article AWR Warehouse in EM12c, Rel 4, Part II and I noticed the following comment:
“A unique setting can be made for one source target from another in the AWR Warehouse, too. So let’s say, you only want to keep three months of one database, but 2 years of another, that is an option.”
I setup a AWR warehouse and used the Forever option as default – but I was wondering if you might tell me how to make the changes allowing different retention periods on a database by database option or provide some link where the method can be found.
Thank you.
Dennis
Hi there, Did You solve this problem ?. I have similar case to process 🙂
No. Did not have time to dig into script.
As I remember the issue was that ETL process wan tto connect to AWR database with TCP on 1521.
Where you can change this and how? I newer found.
BR Igor
This was the TCP rule missing. Pump job from source database was not able to connec to he repo ( oms ) through 1521. Setup was done, jobs are succesfully completed but i have no awrs in repo … ehh. I’ll be back to this awr setup soon.