
AWR Warehouse, Status
So the AWR Warehouse patches are out, but documentation has not officially caught up to it yet, so as we appreciate your patience. I thought I would post about what I went over in my webinar last week when I had the wonderful opportunity to speak to the ODTUG members on this feature that everyone is so anxious to get their hands on.
Let’s start with some of the top questions:
1. Can I just load the AWR data into the OMR, (Enterprise Manager Repository) database?
A. No, it is highly recommended that you do not do this- use a separate database and server to house the AWR Warehouse.
2. What licensing requirements are there?
A. The AWR Warehouse, (AWRW, my new acronym and hashtag, #AWRW) requires the Diagnostic Pack license and with this license, a limited use EE license is included for the AWR Warehouse. This is subject to licensing changes in the future, but at this time, this is a great opportunity considering all the great features that will be included in the AWR Warehouse to house, partition, access and report on via EM12c, etc.
3. Can I query the AWR Warehouse directly?
A. It is another Oracle database, so yes, of course you can!
Behind the Scenes
The AWR Warehouse’s data is sourced from target databases in EM12c, providing the ability to retain AWR data indefinitely or for any period of time you choose. For retail companies or those that do heavy once per year processing, this is gold. The idea that you can do comparisons on performance a year ago vs. today is incredibly valuable.
This data is loaded via an ETL process using an Agent to Agent direct push of the data, initialized by an Enterprise Manager. The actual export on the source database and import on the AWR Warehouse is performed by a DBMS_Scheduler job local to those servers.
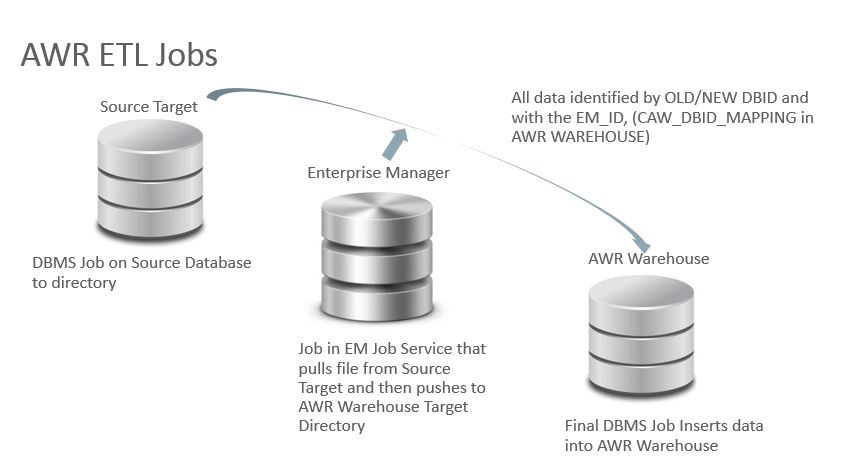
The actual interval on the source database and AWR Warehouse depends on if you’ve just added the database to the AWR Warehouse, (back load of data, requires “catch up”) or if the AWRW ETL load has been disabled for a period of time. There is a built in “throttle” to ensure that no more than 500 snapshots are loaded at any given time and intervals that cause very little to no network traffic in the environment. During the catchup that required a full 500 snapshots to load on a VM test environment, I was thrilled to see it took a total maximum execution time of less than 12 minutes and 2GB of data. The network latency was nominal, too.
For the next sections, you will notice the naming convention in jobs and objects of “CAW” either in the beginning or middle of the name. CAW stands for Consolidated AWR Warehouse and you can use %CAW% to help filter to locate via queries in any AWRW related search, including on source databases, (targets).
Source ETL Job
The job on the source database, (targets) to datapump the AWR data from the source for a given snapshot(s) to reside on an OS directory location to be “pushed” by the agent to agent onto an AWR Warehouse OS directory location.
DBMS Scheduler Job Name: MGMT_CAW_EXTRACT
Exec Call: begin dbsnmp.mgmt_caw_extract.run_extract; end;
How Often: 3 Hour Intervals if “playing catch up”, otherwise, 24 hr interval.
AWR Warehouse Job
This is the job that loads the data from source targets, (databases) to the AWR Warehouse.
DBMS Scheduler Job Name: MGMT_CAW_LOAD
Exec Call: begin dbsnmp.mgmt_caw_load.run_master;
How Often: 5 Minute Intervals
Biggest Resource Demand from the “run_master”:
begin dbms_swrf_internal.move_to_awr(schname => :1); end;
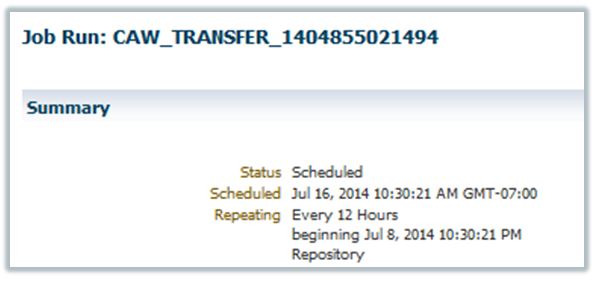
EM Job Service
The EM12c comes into play with the ETL job process by performing a direct agent to agent push to the AWR Warehouse via a job submitted to the EM Job Service. You can view the job in the Job Activity in the EM12c console:
Under the Hood
The additions to the source database, (target) and the AWR Warehouse once adding to the AWR Warehouse or creating an AWR Warehouse is done through the DBNSMP schema. The objects currently begin with the CAW_, (Consolidated AWR Warehouse) naming convention, so they are easy to locate in the DBSNMP schema.
AWR Warehouse Objects
The additions to the DBSNMP schema are used to support the ETL jobs and ease mapping from the Enterprise Manager to the AWR Warehouse for AWR and ASH reporting. The AWR schema objects that already exist in the standard Oracle database are updated to be partitioned on ETL loads by DBID, Snapshot ID or a combination of both, depending on what the AWR Warehouse developers found important to assist in performance.
There are a number of objects that are added to the DBSNMP schema to support the AWRW. Note the object types and counts below:
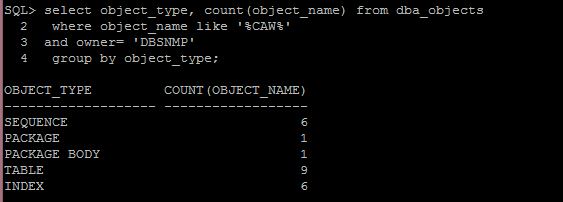
The table that is of particular interest to those of you with AWR queries that are interested in updating them to be AWRW compliant, is the CAW_DBID_MAPPING table:
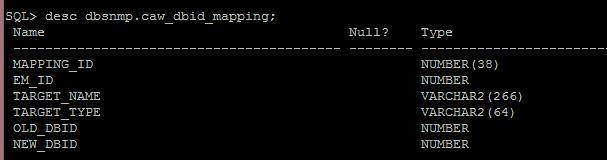
You will be primarily joining the AWR objects DBID column to the CAW_DBID_MAPPING.NEW_DBID/OLD_DBID to update those AWR scripts.
An example of changes required, would be like the following:
from dba_hist_sys_time_modelstm, dba_hist_snapshot s, gv$parameter p, dbsnmp.caw_dbid_mapping m where stm.stat_name in (‘DB CPU’,’backgroundcpu time’) and LOWER(m.target_name)= ‘&dbname‘ and s.dbid= m.new_dbid and s.snap_id = stm.snap_id and s.dbid = stm.dbid and s.instance_number = stm.instance_number and p.name = ‘cpu_count’ and p.inst_id = s.instance_number)Notice that the simple change with the addition of the mapping table and addition to the where clause has resolved the requirements to query just the data for the database in question by DBID.
I’ve included some updated scripts to use as examples and hopefully give everyone a quick idea on how to work forward with the AWR Warehouse if you so decide to jump headfirst into querying it directly.
Source Database Objects
There are only a couple additions to the Source Databases when they become part of the AWR Warehouse.
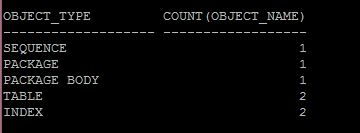
The objects are only used to manage the AWR extract jobs and track information about the tasks.
CAW_EXTRACT_PROPERTIES : Information on ETL job, dump location and intervals.
CAW_EXTRACT_METADATA : All data about extracts- times, failures, details.
So….
Do you feel educated? Do you feel overwhelmed? I hope this was helpful to go over some of the processes, objects and information for AWR queries regarding the AWR Warehouse and I’ll continue to blog about this topic as much as I can! This feature is brand new and as impressed and excited as I am about it now, I can’t wait for all there is to come!
Hi Kellyn,
thank you for this great insight to AWRW.
May I ask you to go a little bit more into detail about the ETL Job in a RAC environment? Does every agent extracts the data or is only one agent responsible? And is a shared storage needed for this?
As my current company is very creative in separating servers via firewalls, can you tell us about the requirements and techniques of the agent to agent push?
thank you very much,
@martinberx