SQLTXPLAIN and the AWR Warehouse- Part II
I finally have a moment to look into my “hacked” SQLT XPRECT/XTRACT runs and see if the changes I made were enough to run properly with the AWR Warehouse.
The answer is yes and no… and maybe “it depends”… 🙂
The Results
The data from the AWR Warehouse to pull the corresponding data for the appropriate SQL_ID from the correct source database in the AWR repository worked, but the environment information still populates incorrectly, as I didn’t update anything outside of the get_database_id function in the SQLT$A package and the executables that call it, as documented in my earlier blog post.
The first indicator that my assumptions that additional functions would need to be updated were verified when I noted the environment values in the main html page, the main entry point into the zip file provided as output in any SQLT run:
![]()
The SQL_ID was run against the SH database, but it instead shows the information for the AWR Warehouse, displaying incorrectly. The issue is its populating the database name, DBID and the shortname from the local views, (v$instance, v$database, etc…)
The CBO environment and system statistics are also wrong, as it pulls this information from the database and this is simply the AWR repository data, not the database the data resides in:
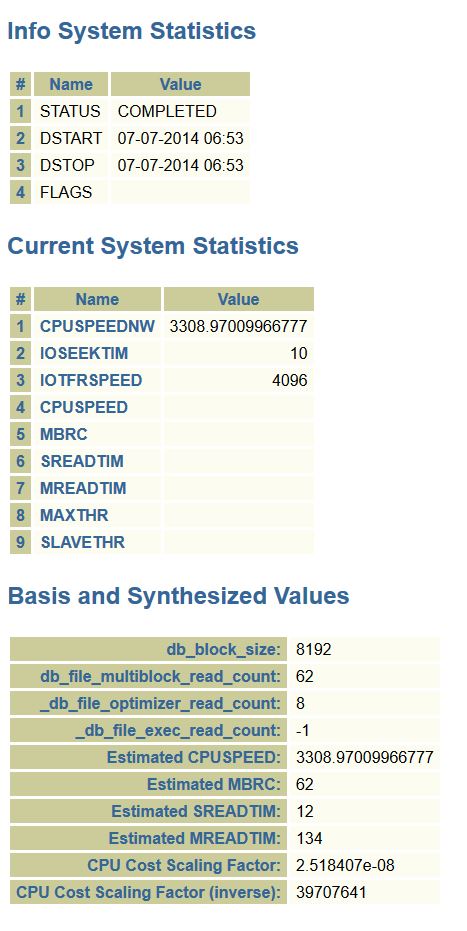
Yes, the statistics and initialization parameters have no way to currently pull from the dba_hist tables, which means that we have the wrong data for most of the higher level info on the main HTML page.
Where It’s Right
Where I made changes, which were minimal vs. what was required, is where it displays correctly. The cursor sharing, the SQL information, along with SQL_ID data is all correct for the statement at hand.
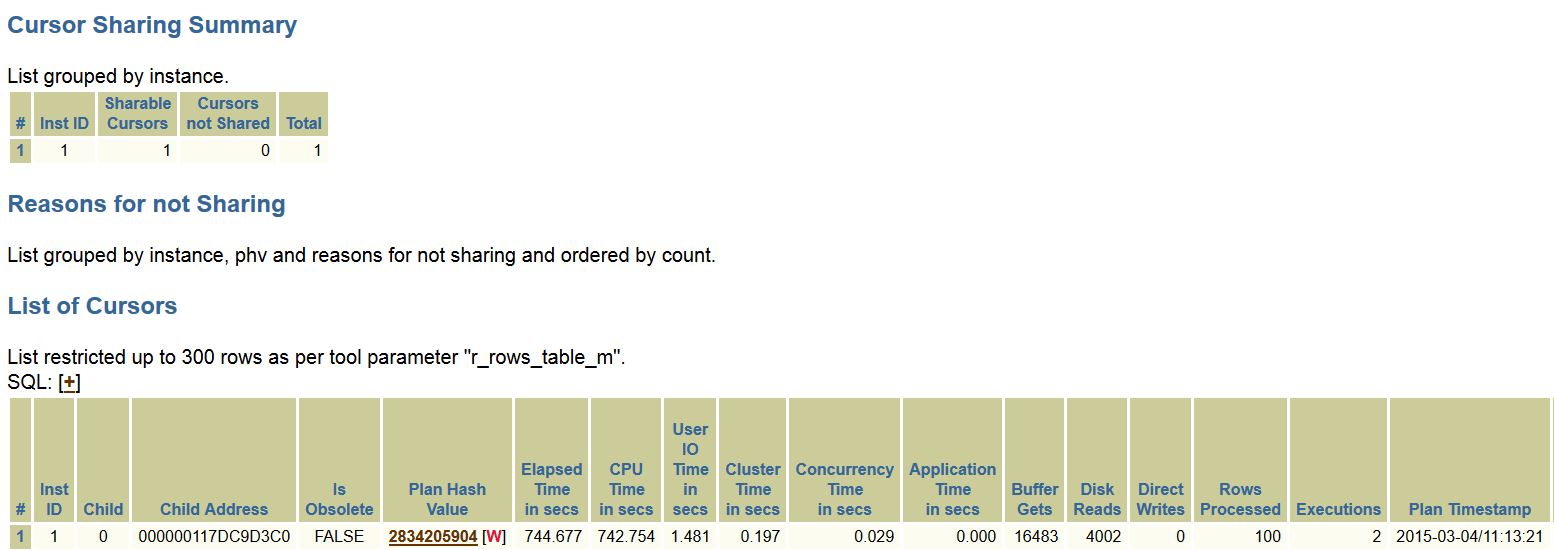
The bind peek info is correct, too-
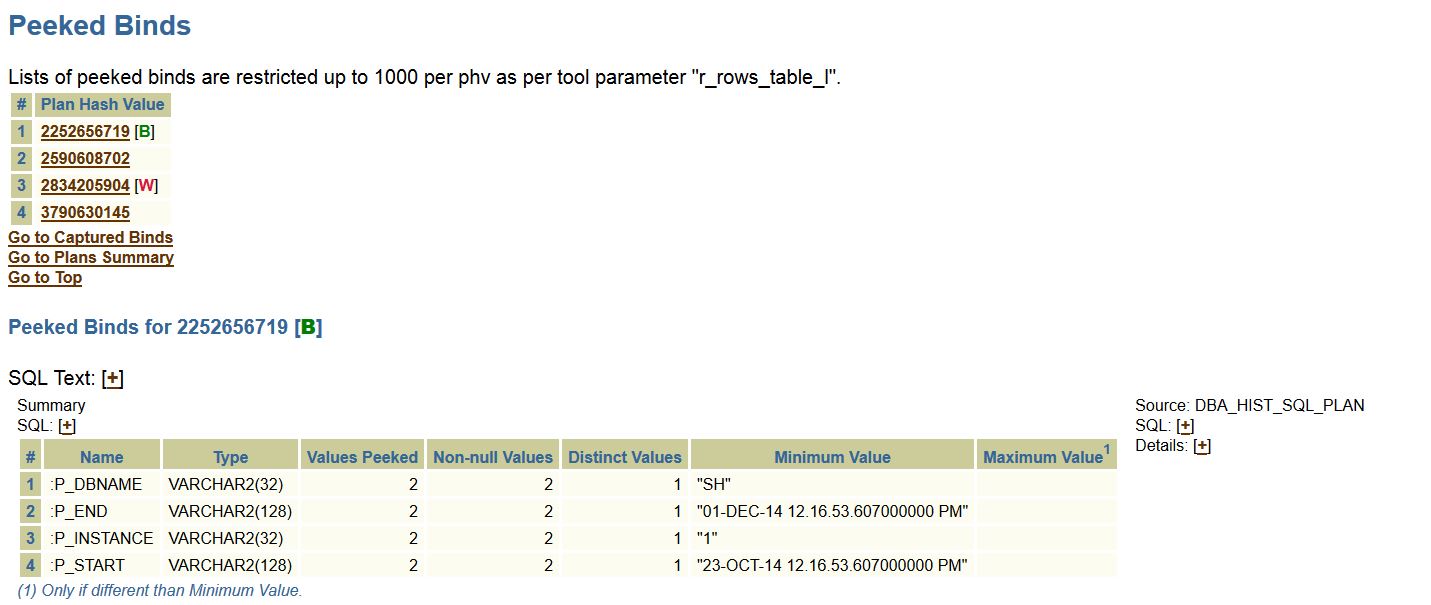
You can quickly view that the data is pulled from the DBA_HIST_SQL_PLAN table and since I’m pushing the correct SQL_ID and DBID to the query, it responds with the correct information in return.
I have results in any source that shows the DBA_HIST_SQL_PLAN and distinct failures when anything queries the GV$SQL_PLAN. This should be expected- the AWR Warehouse is only going to house the SH database information for this SQL_ID in the DBA_HIST objects. The GV$ objects aren’t going to know anything about SH source database information.
Success Rate
So how successful was I? About 30%… 🙂
Any objects, including the r_rows objects populated as part of the SQLT runs, were successful if they sourced from the Automatic Workload Repository, (WRH$, WRI$ and WRM$ objects, which feed the DBA_HIST* views) and failed when they sourced from an GV$ or V$ object. I also had to ensure that they had the appropriate DBID called, along with the SQL_ID. Without this added element, failures also occurred.
Recommendations for Change
Additional Changes that need to be made to complete the transition to AWR Warehouse compliance would include:
At the time of installation, the additional option for not just tuning pack, but also add “A” for AWR Warehouse. If this option is chosen, a second version of the SQLT$A package is then deployed, along with the executables for the XPRECT and XTRACT SQL statements.
SQLT$A Package would require updates for the following functions:
- get_database_id
- get_database_name
- get_sid
- get_instance_number
- get_instance_name
- get_host_name
- get_host_name_short
The XPRECT and XTRACT would then require an additional parameter addition- dbname.
So instead of:
>START /u01/home/sqlt/run/sqltxprext.sql aycb49d3343xq <sqlt password>
it would be:
>START /u01/home/oraha/kellyn/sqlt/run/sqltxprext.sql aycb49d3343xq <dbname> <sqltpassword>
Carlos and Mauro were wonderful and introduced me to Abel, so I’ll be passing this along to him, so cross your fingers and lets see if we can get this valuable tool working with the AWR Warehouse….and soon! 🙂