
Delphix- Cannot Provision from Part of Timeflow
This was received by one of our Delphix AWS Trial customers and he wasn’t sure how to address it. If any others experience it, this is the why it occurs and how you can correct it.
You’re logged into your Delphix Administration Console and you note there is a fault displayed in the upper right hand console. Upon expanding, you see the following warning for the databases from the Linux Target to the Sources they pull updates from:
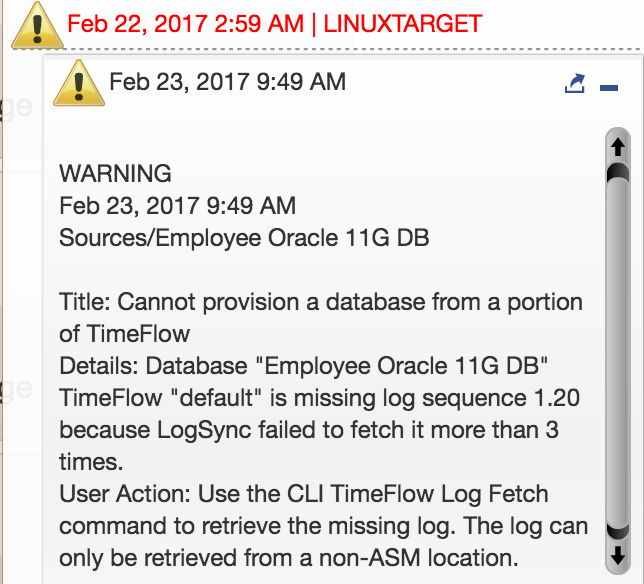
Its only a warning and the reason it’s only a warning is that it doesn’t stop the user from performing a snapshot and provisioning, but it does impact the timeflow, which could be a consideration if a developer were working and needed to go back in time during this lost time.
How do you address the error? Its one that’s well documented by Delphix, so simply proceed to the following link, which will describe the issue, how to investigate and resolve.
Straightforward, right? Not so much in my case. When the user attempted to ssh into the linux target, he received an IO error:
$ ssh delphix@xx.xxx.xxx.x2 $ ssh: connect to host xx.xxx.xxx.x2 port 22: Operation timed out
I asked the user to then log into Amazon EC2 dashboard and click on Instances. The following displayed:
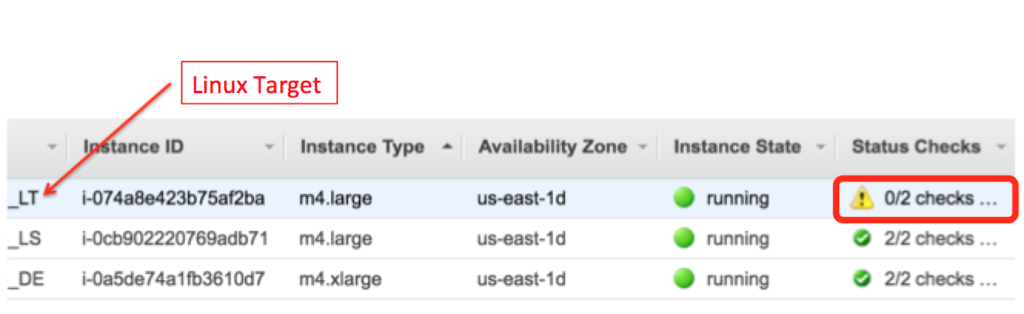
Oh-oh….
By highlighting the instance, the following is then displayed at the lower part of the dashboard, displaying that their is an issue with this instance:

Amazon is quickly on top of this once I refresh the instances and all is running once more. Once this is corrected and all instances show a green check mark for the status, then I’m able to SSH into the console with out issue:
$ ssh delphix@xx.xxx.xxx.x2 Last login: Tue Feb 21 18:05:28 2017 from landsharkengine.delphix.local [delphix@linuxtarget ~]$
Does this resolve the issue in the Delphix Admin Console? Depends… and the documentation linked states that the problem is commonly due to a problem with network or source system, but in this case, it was the target system that suffered the issue in AWS.
As this is a trial and not a non-production system that is currently being used, we will skip recovering the logs to the target system and proceed with taking a new snapshot. The document also goes into excellent ways to deter from experiencing this type of outage in the future. Again, this is just a trial, so we won’t put these into practice for a trial environment that we can easily drop and recreate in less than an hour.
Tips For Real Delphix Environments
There are a few things to remember when you’re working with the CLI:
-If you want to inspect any admin information, (such as these logs, as shown in the document) you’ll need to be logged in as the delphix_admin@DOMAIN@<DE IP Address>.
So if you don’t see the “paths” as you work through the commands, it’s because you may have logged in as sysadmin instead of the delphix_admin.
-If you’ve marked the fault as “Resolved”, there’s no way to resolve the timeflow issue, so you’ll receive the following:
ip-10-0-1-10 timeflow oracle log> list timeflow='TimeFlow' missing=true No such Timeflow ''TimeFlow''.
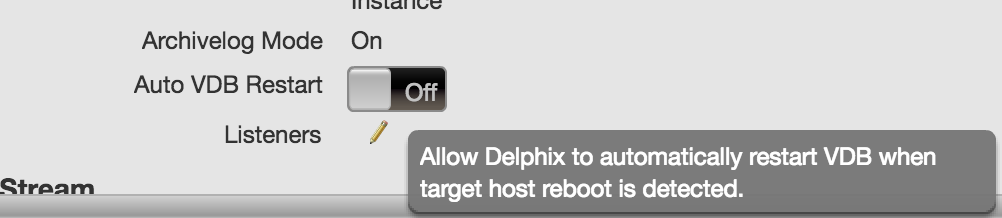
-If the databases are down, it’s going to be difficult for Delphix to do anything with the target database. Consider updating the target to auto restart on an outage. To do so, click on the database in question, click on Configuration and change it to “On” for the Auto VDB Restart.
Here’s a few more tidbits to make you more of an expert with Delphix. Want to try out the free trail with AWS? All you need is a free Amazon account and it’s only about 38 cents an hour to play around with a great copy of our Delphix Engine, including a deployed Source and Target.
Just click on this link to get started!