
Yeah, so I did it- I installed SQLTXPLAIN, (SQLT) on the AWR Warehouse! From previous experience with this fantastic tool, I was pretty sure I’d have some great new adventures with the AWR Warehouse data and I wanted to try and test out the AWR pieces of this tool with the Warehouse. This is a work in progress, so I’m going to do this blog in multiple parts to ensure we don’t miss anything.
Installation
I didn’t expect SQLT AWR features to work out of the box. I still needed to install it, run a few reports and see what would trip it up from using the AWR Warehouse repository data.
The installation was pretty much standard- no differences from the requirements on any other database, including a default tablespace, connection information for the AWR Warehouse repository and other pertinent data. The one thing I did do and you should do to work with the AWR Warehouse is to use the “T” value for having the Tuning and Diagnostic Pack, so you can use its’ features with AWR Warehouse.
- Licensed Oracle Pack. (T, D or N)
You can specify T for Oracle Tuning, D for Oracle Diagnostic or N for none. If T or D is selected, SQLT may include licensed content within the diagnostics files it produces. Default isT. If N is selected, SQLT installs with limited functionality.
The features that are currently supported with the AWR Warehouse from the command line are the following, per the Oracle Support Doc (Doc ID 1614107.1)
SQLT may use the Oracle Diagnostic and/or the Oracle Tuning Packs if your site has a license for them. These two provide enhanced functionality to the SQLT tool. During SQLT installation you can specify if one of these two packages is licensed by your site. If none, SQLT still provides some basic information that can be used for initial SQL diagnostics.

With the installation complete, now the fun starts, or that’s what I thought!
The DBID Conundrum
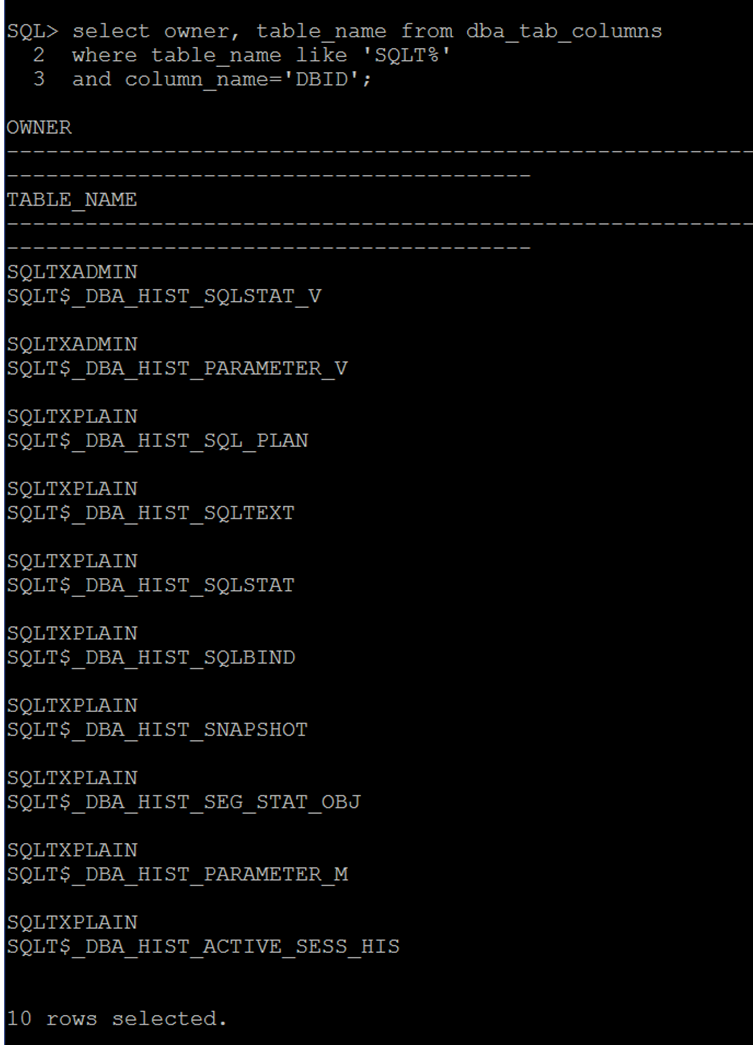
For my AWR Warehouse environment, (my tiny one that suffices for my testing currently… :)) I can gather the information on my databases that I’m consolidating the performance data and show the “source database” that is of interest. I want to see if I can run AWR xtracts and other processes from the warehouse or if it will fail. My initial query to look at what exists in my AWR Warehouse is going to take me to the DBNSMP.CAW_DBID_MAPPING table:
SQL> select new_dbid, target_name from dbsnmp.caw_dbid_mapping;
NEW_DBID ---------- TARGET_NAME ----------------------------------------------------------------- 3017376167 cawr 2710603395 ß This is the one we want to work with! SH 2973036624 repo
Which we can match up to the distinct DBIDs in one of the AWR objects that also contain SQL_IDs and PLAN_HASH_VALUE data:
SQL> select distinct DBID from <insert AWR Object Here>; DBID ---------- 2710603395 2973036624 3017376167
As this is a 12.1.0.2 database, (expected with an AWR Warehouse repository, we recommend 12.1.0.2) I’ve granted the inherit privileges that are required for new DB12c execution of SQLT by SYS, but I’m still having issues even running the AWR centric SQT features. I’m curious why, but I have some ideas where the problems might lie.
If you run a SQLID Specific, (or any AWR report) report, it will display what Instance the AWR will to choose to run the report against:

As we can see, we have multiple DBIDs, Instance name and host information, (although I’ve hidden that… :))
SQLT And The Quest For the DBID Value
The SQLT, I first assume must do something very similar, bypassing the ability to utilize the other DBID data and coming back with an error stating that the SQL_ID’s doesn’t exist when you attempt to run reports against them:
SQL> START /u01/home/kellyn/sqlt/run/sqltxprext.sql 8ymbm9h6ndphq <SQT Password>

To verify the issue, I run the XTPREXT with a SQL_ID from the repository DBID, which would show in the local AWR:
SQL> START /u01/home/kellyn/sqlt/run/sqltxprext.sql aycb49d3343xq <SQLT Password>
Per the run of the successful SQL_ID, I was able to view the following from the sqlxtract.log the step that sets the DBID:
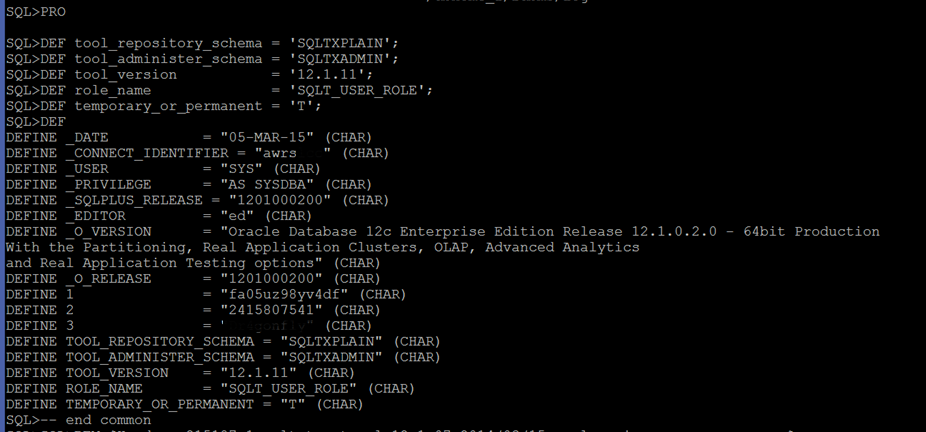
We can see in the above log the DEFINE 2 passes in the DBID for the For me to take advantage of SQLT, I need to find a way around the code that is setting the DBID and other instance level information. The objects exist to support an AWR Warehouse design, just as with a local AWR, the DBID is then populated into the SQLT objects to produce reports:
Now if I can update the code that populates these tables to produce the reports, then SQLT becomes AWR Warehouse compliant.
Making SQLT AWR Warehouse Compliant
The code that needs to be updated are in all coming from one location and due to the “clean” coding practices from Carlos, Mauro and others, this is quite simple to perform.
Working with the package body, sqcpkga.pkb and the package source sqcpkga.pks. We’ll identify the following areas that the AWR Warehouse will be dependent upon-
You’ll see the calls that are populated with the values:
FUNCTION awr_report_html ( p_dbid IN NUMBER, p_inst_num IN NUMBER, p_bid IN NUMBER, p_eid IN NUMBER, p_rpt_options IN NUMBER DEFAULT 0 )
These values are then part of the package body:
/* ------------------------- * * public get_database_id * * ------------------------- */ FUNCTION get_database_id RETURN NUMBER IS l_dbid v$database.dbid%TYPE; BEGIN EXECUTE IMMEDIATE 'SELECT dbid FROM v$database'||s_db_link INTO l_dbid; RETURN l_dbid; END get_database_id; /*************************************************************************************/
Now this isn’t going to do me any good “as is” with the AWR Warehouse, where we have multiple dbids and instance ID’s but we need to pass the value in properly.
We’ll start going through the changes step by step. The code is well written, but involved in what it produces and we’ll ensure that we take each one into consideration before updating and making it AWR Warehouse compliant.
I foresee this as part of the installation someday, (this is for you, SQLT guys)- If the installer states, as we demonstrated earlier, that they have the tuning pack, then the install will then know you have licenses to use the AWR and will switch from the existing code to the one that I will propose to make it AWR Warehouse complaint. The AWR Warehouse, as we’ve discussed, retains the DBID and instance allocation for all databases added to the AWR Warehouse repository, so we just need to make sure we use it if we are allowed by our licensing.
I focused on the dba_hist_database_instance object, as it contains about 95% of the pertinent data that SQLT was getting from the v$database, v$instance, gv$** objects and so on.
SQL> desc dba_hist_database_instance; Name Null? Type ----------------------------------------- -------- -------------- DBID NOT NULL NUMBER INSTANCE_NUMBER NOT NULL NUMBER STARTUP_TIME NOT NULL TIMESTAMP(3) PARALLEL NOT NULL VARCHAR2(3) VERSION NOT NULL VARCHAR2(17) DB_NAME VARCHAR2(9) INSTANCE_NAME VARCHAR2(16) HOST_NAME VARCHAR2(64) LAST_ASH_SAMPLE_ID NOT NULL NUMBER PLATFORM_NAME VARCHAR2(101) CON_ID NUMBER
Armed with this information, we can then make the first of many necessary changes-
/* ------------------------- * * public get_database_id * * Enhancement by KPGorman * AWRW compliant, now passes in DBNAME * 03/09/2015 * ------------------------- */ FUNCTION get_database_id (p_dbname IN VARCHAR2) RETURN NUMBER IS l_dbid.dbid%TYPE; BEGIN EXECUTE IMMEDIATE 'SELECT distinct(dbid) FROM DBA_HIST_DATABASE_INSTANCE'||s_db_link || 'where DB_NAME = p_dbname' INTO l_dbid; RETURN l_dbid; END get_database_id; /*************************************************************************************/
There were six changes that were required to this code to get started-
- get_database_id
- get_database_name
- get_sid
- get_instance_number
- get_instance_name
- get_host_name
- get_host_name_short
Now there are more areas that need attention, like code that populates the database version, the OS platform, database properties, etc. These are pulled from the instance level and not from the AWR tables, too.
Luckily for me, this is all set in one place and not all over in the code, (great development work is wonderful to see!) There is some other code that is using the gv$** to ensure it captures global data for RAC environments, too. Again, I have to stress how well this is written and how easy they are making my job for my Proof of Concept, (POC).
After making the required changes, I recompile the one package and package body, along with the sqltxprext.sql in the SQLT/run director that is involved. The objects inside the database that I’m working with are in the SQLTXADMIN schema- not the SQLTXPLAIN schema. Keep in mind, this is just for the POC, but for a proper installation, I would expect the installer for SQLTXPLAIN to look and see if we have the tuning pack and then with this verification, switch to the correct SQLT$A package and executables to be released and ensure we are using the AWR data instead of the v$** objects.
SQL> alter package SQLTXADMIN.SQLT$A compile body; Package body altered. SQL> alter package SQLTXADMIN.SQLT$A compile; Package altered.
Moment of Truth
Now that I’ve made the changes and everything has compiled successfully, it’s time to test it out with a SQL_ID from one of my source databases. Now one thing to keep in mind, I left for the OUGN Norway conference between the start of this POC and the end, so I had to pick up where I left off. It took me some time to verify that I’d left off in the right spot and I had to make a few more changes for the host data, etc., but we’re ready to run this now!
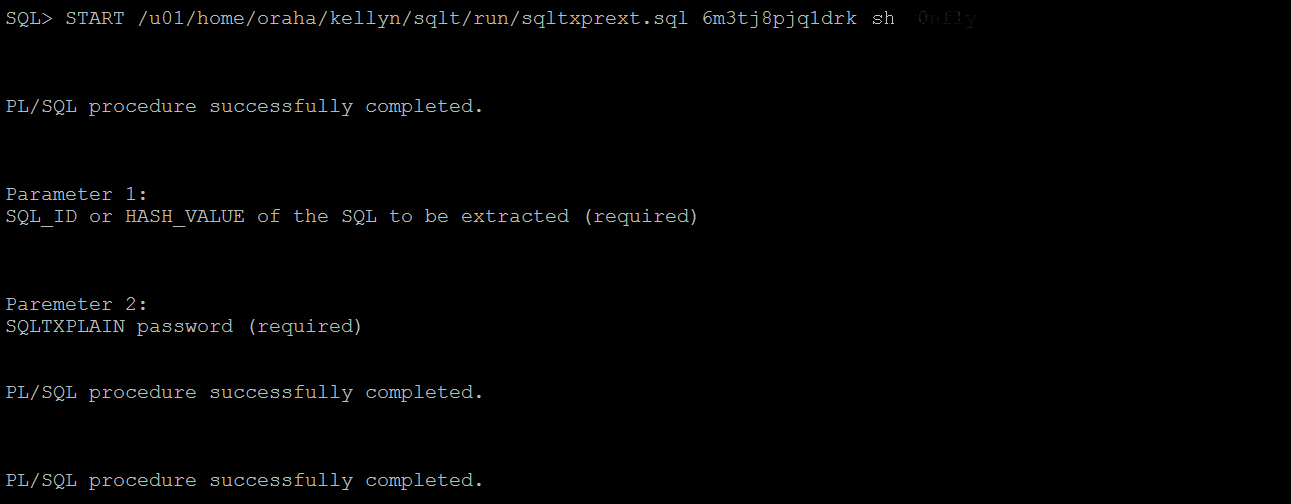
I now pass the DBID and was initially worried about a few of the data results in the screen, but after viewing the sqlxtract.log, I was less worried. Most of the values that are required to pass to SQLT to ensure proper handling is correct, but it appears I have a couple more changes to implement before I’m finished making EVERYTHING compliant. The parameters for the call look very good upon first inspection though:
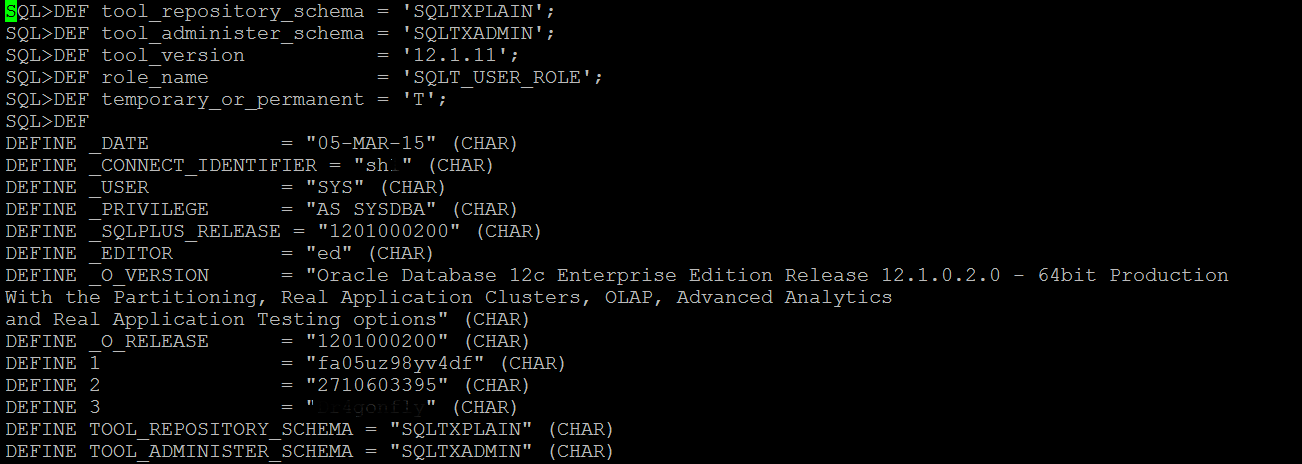
The DEFINE 2 now shows the correct DBID, as does the DEFINE_CONNECT_IDENTIFIER. The zip file is created as part of the XPRECT output and I just need to dig into it to see if there is anything more I need to change that I might have missed vs.making any assumptions from the sqltxtract.log, which is a bit high level and jumbled with execution errors vs. the demands I’m making on this command line tool.
Thanks for staying with me on this one and stay tuned for the output to see how successful I was! 🙂

3 Comments on “SQLTXPLAIN and the AWR Warehouse, Part I”
Comments are closed.