Designing for Multi-Platform Databases: A SME’s Perspective
When building products that interact with multiple database platforms, the complexity can be both a challenge and an opportunity. For
Read More
Making Technology Bulletproof
When building products that interact with multiple database platforms, the complexity can be both a challenge and an opportunity. For
Read MoreAlong with presenting the keynote at SQL Saturday Oregon this weekend, I will be taking the SQL Train up to
Read MoreI’ve been pretty busy with work and travel, but I finally got an official Silk Github repository to publish a
Read MoreWith my upcoming session on “Migrating Oracle Workloads to Azure IaaS” this week at PASS Virtual Summit 2020, I wanted
Read MoreThis is a 2-part blog post, the first in the series can be found on the Microsoft SQL Server blog
Read MoreSo you want to run mssql-cli on Ubuntu Linux, but you received a number of errors and even if you
Read MoreIn the previous blog posts, we learned how to set up the first part of a standard shell script- how
Read MoreAzure Directory is available with Linux SQL Server 2019 in Preview and as I was setting it up in my
Read More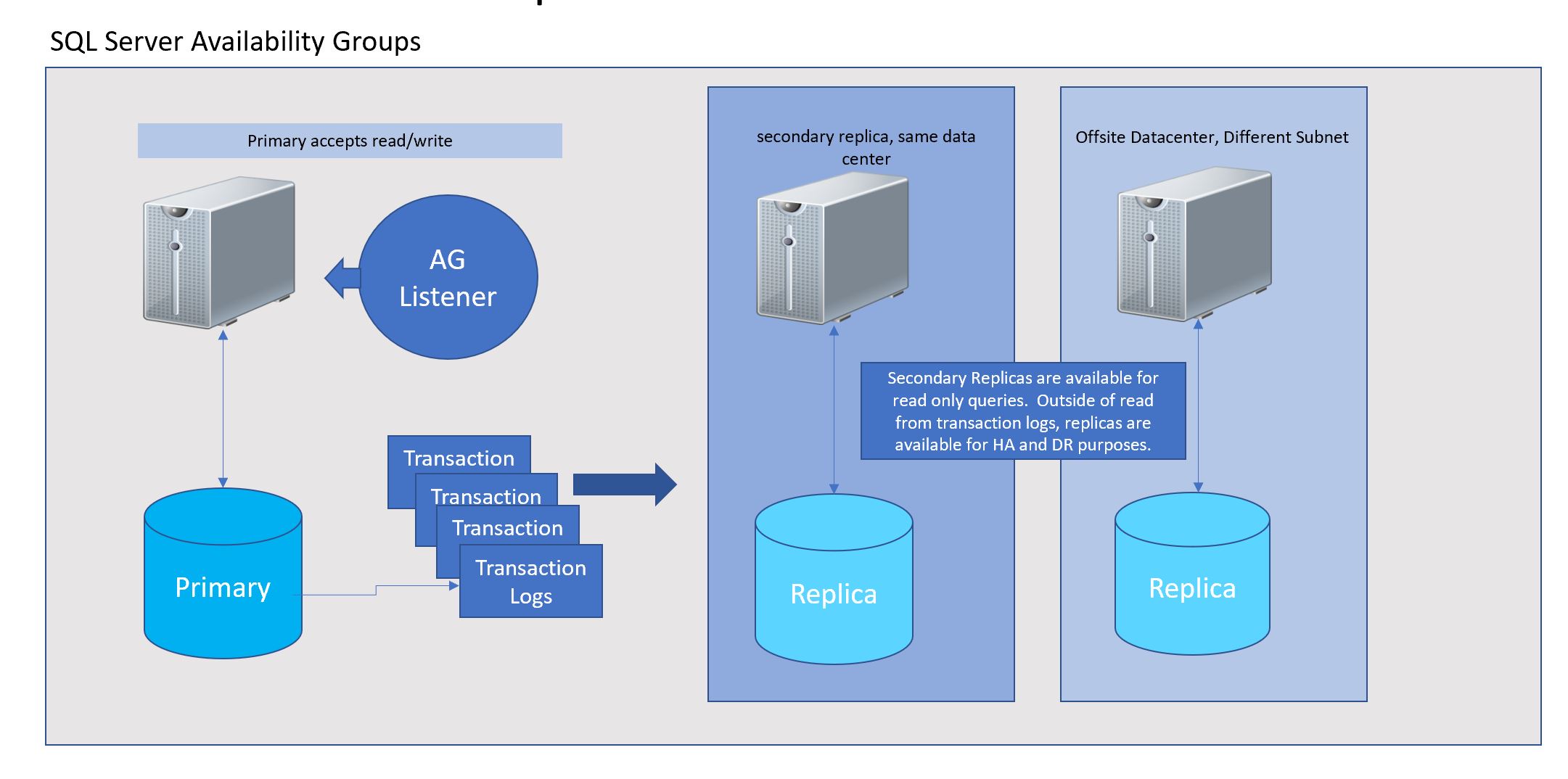
As I have seen the benefit for having a post on Oracle database vs. SQL Server architecture, let’s move onto
Read MoreThere are a lot of DBAs that are expected to manage both Oracle and MSSQL environments. This is only going
Read MoreI learned a long time ago, that the quickest way to do something was to not do it at all.
Read MoreSo Tracy Boggiano told me about the great First Responder kit that Brent Ozar had available to use with sp_Blitz
Read MoreSo I made it to PASS Summit 2018. After a flight from an airport with one gate- yes, you heard
Read MoreI’ve been hesitant to post too much on my blog until since the hack, as there were some residual issues
Read MoreTim and I just arrived back in Colorado yesterday and just arrived- as in Grand Junction, Colorado on the western
Read MoreI just finished teaching an 8 hour pre-con at SQL Saturday Indianapolis on Essential Linux for the DBA. The focus
Read MoreSo I haven’t opened Visual Studio in….oh….let’s just say it’s been a few years…:) I had a project that I
Read MoreSo many have asked me when I’m starting at Microsoft and the official date is Monday, June 11th now. Many
Read More