
There are a lot of DBAs that are expected to manage both Oracle and MSSQL environments. This is only going to become more common as database platforms variations with the introduction of the cloud continue. A database is a database in our management’s world and we’re expected to understand it all.
Its not an easy topic, but I’m going to post on it, taking it step by step and hopefully the diagrams will help. Its also not an apple to apple comparison, so hopefully, but starting at the base and working my way into it with as similar as comparisons as I’m able to with features, it will make sense for those out there that need to understand it.
We have a number of customers that are migrating Oracle to Azure and many love Oracle and want to keep their Oracle database as is, just bringing their licenses over to the cloud. The importance of this is they may have Azure/SQL DBAs managing them, so I’m here to help.
To begin, let’s start with a diagram that I *believe* best compares the basic, (and pretty high level) comparison between the two database platforms:
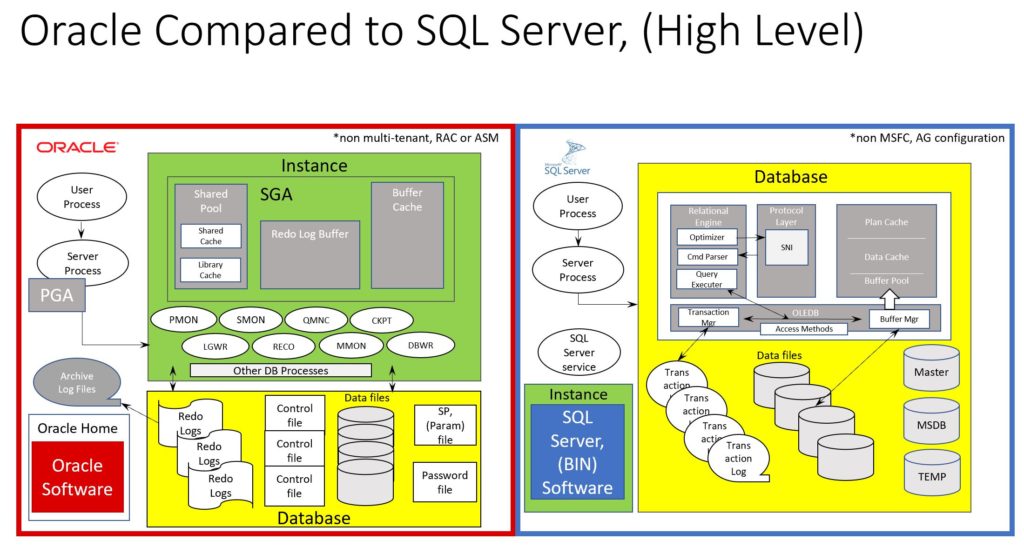
Instance vs. Database
The first thing you’ll notice is what Oracle refers to as an INSTANCE is different to what SQL Server calls one.
Oracle’s instance is most closely related to what SQL Server calls their database, (although it includes the files that Oracle includes in their description, too) and the Oracle home is *relatively* SQL Server’s version of an instance.
Please also note that the Oracle architecture in the diagram isn’t 12c+ multi-tenant, a RAC, (Real Application Cluster) or has an ASM, (Automatic Storage Management) secondary instance managing the database files. All of this we’ll take on in further posts, but for today, we’ll stick to the generic, traditional architecture and simplest installation.
Background Processes
The second major difference is in the way of background processing. Where Oracle has an Oracle executable and SQL Server has one for it’s database engine, too, Oracle also has numerous background processes running for each database. These processes each perform a job or back up another process as part of a secondary responsibility. SQL Server is multi-threaded architecture and although I can quickly assess what threads are performing what responsibilities inside the database, I’ve been unable to assess this from the server level tools, where in Oracle, each process is clearly named at the OS level of its description.
Two of the major background processes are the PMON, (Process Monitor) and SMON, (System Monitor, but you will hear some people refer to it as the Session Monitor). If either of these processes die or are killed, the database instance, (i.e. the running processes and accessibility) will discontinue.
Other important background processes, like RECO, (Recovery) DBWR, (Database Writer) LGWR, (Log Writer) QMNC, (Queueing Coordinator) and CKPT, (Checkpoint) address important and obvious responsibilities in a relational database. Most of the time, you can kill these individual processes and the database will restart the process and recover without the instance failing.
Performance Data Collection
There are also two memory processes, MMON, (Manageability manager) and MMNL, (manageability light) that are memory allocations and processing isolated to the Automatic Workload Repository, (AWR) and Active Session History, (ASH). For those in the MSSQL world, these are like the Query Store and Dynamic Management Views, (DMV) performance and session data. One of the important design features of the memory buffer isolated for this work is that it writes one way while the users read the other, eliminating much, if any locking. There is both the V$ view data and then a set of aggregated snapshots, (AWR) and samples, (ASH, also written to the snapshots) written to the AWR repository into the SYSAUX Tablespace.
Tablespace = Filegroups
There’s that funny word, too- “Tablespace”. A tablespace isn’t much different than “Filegroups” in MSSQL. Its just a way of grouping logical objects into a logical space, inside a datafile.
With the introduction of multi-tenant, more Oracle emphasis is shifting from schema centric data to having separate tenants, i.e. pluggable databases. This means that the architecture is becoming more similar to SQL/Azure DB, along with other multi-tenant databases and with that, simpler datafile and tablespace design. Having all the data in one tablespace isn’t viewed as negatively as it once was, along with simplifying the management of data, databases and development.
Control Files
Control Files are the God controls for the database. They are binary files that contain everything from transactional status in the database, undo and redo sequence to physical status of data files. Without a control file, a DBA is in a world of hurt to recover an Oracle database. Having mirrored copies of the control file is one of the first things a DBA learns as part of DBA 101.
Redo Logs
These are another important aspect of Oracle database architecture. Each database contains an UNDO tablespace that tracks all undo if something is rolled back. All of this undo, along with any redo, is written to the REDO logs. These are created in sets, just like transaction logs to handle ongoing workloads, while a second is archiving work and another is available. The busier the database, the larger and more numerous the redo logs are. These are also mirrored in case of corruption or loss, as they are necessary for recovery to undo and redo a database back to an assessible state.
The redo logs are written to archive logs on a regular interval to ensure the database can be recovered for PIT, (Point in Time) recovery situations from backup.
SP and Password Files
The SP, (Parameter) file is binary, but was once a text file called simply the pfile, so you may hear this term as well for those still using it. Similar to the integrated SP_CONFIGURE, it is used to set up the parameters for the database configuration, including version, naming, etc. The file is included in backups and can be copied to the text, pfile version easily.
These parameters can be updated from the database management console, (UI) or the command line with the “in memory” option, which means a database cycle will be required to solidify the change or for many, scope=both, which would make the change immediate and written to the file.
The Password file is configuration of password management for the database, including remote connectivity access for management. A shared option means that it can be shared among databases, eliminating extra management and setting the SYSDBA management of the database.
PGA- What is it?
PGA, (Process Global Area) is an allocation of memory used for sorting, hashing and PL/SQL tables, among a few things. As Oracle doesn’t have a TEMP database to perform these tasks and 99% of indexes are heap, not clustered, having this memory is essential for increased performance. The memory is outside of the SGA, (System Global Area) and its also outside of the configuration for SGA memory. This is important when a DBA is sizing out a machine and knowing that there are distinct limits per process, process type and workload for PGA allocation, no matter how much PGA is set in the SP File.
Why is the sizing of the PGA important? If you don’t have enough PGA allocated or if the SQL is written poorly, a process won’t run inside of memory and will swap to TEMP tablespace. Unlike a TEMP database, a tablespace is disk allocation and disk, unless SSD, if very slow.
I’m hoping this was a good introduction into how Oracle is similar and different from SQL Server. I’ll try to continue with this topic and dig in deeper as we go along and hopefully I didn’t melt anyone’s brain.



3 Comments on “Oracle vs. SQL Server Architecture”
Comments are closed.