
I’ve been told many times that the OMS for EM12c can take quite some time to start on Windows. Some told me it took anywhere from three to up to fifteen minutes and wanted to know why. I’ve done some research on the challenge and it is a complex one.
Let’s start this post by stating that even though I’m focusing on the OMS service that is part of the Windows installation of EM12c from Oracle, that in no way is it to blame, nor is it the only application to have this problem, (so this post may help many others) and it has more to do with over-engineering on MANY different non-Oracle levels and in no way is it a bug. At the same time, it can really impact the quality of user experience with EM12c on Windows and it helps if you know WHAT is causing the challenge vs. what will easily have fingers pointed to as the blame. We all know that Oracle is blamed until proven innocent, so it’s important that we understand what is happening to correct the problem vs. just pointing fingers.
As most DBAs aren’t as familiar with the Windows OS Platform, lets quickly review what a Windows service is and why its important-
A Microsoft Windows services, formerly known as NT services, creates long-running executable applications that run in their own Windows sessions. These services can be automatically started when the computer boots, can be paused and restarted, and do not [require a] user interface.
When installing Enterprise Manager 12c on Windows or installing even the Oracle database on the Microsoft Windows OS platform, a service is created to support the application. This service can be created a number of ways, but for Oracle, they support the following:
oradim - new -[sid] -intpwd [password] -maxusers [number] -startmode [auto|manual] -spfile [directory location of spfile]
emctl create service [-oms_svc_name <oms_service_name> -user <username> -passwd <password>]
and then we have Windows method of a service command:
sc create [service name] -binPath= "[path to executable to start app and argument]" start= [auto|manual] displayName= [name to display]
Each of these options are supported to create many of the different services that are needed to support different features/targets in Enterprise Manager and are used as part of the installation process via the Database Configuration Assistant, the Network Configuration Assistant and the Oracle Installer.
One of the enhancements that they are working on for EM12c is moving the java thread startup and stop from serial to multi-threaded processing. This is going to speed up the start and stop of the OMS extensively, (anyone tracing the startup of an OMS to see where time is being spent will undoubtedly see that over 80% is the weblogic tier….)
Until this enhancement is made, the extended time trips a few safety measures that are built at a number of levels into services to ensure they stay up. If a service isn’t up, well, you aren’t going to be using the application, so unfortunately for us, this is where the OCD of the development world has come back to haunt us…. 🙂
Tracing and Advanced Logging
First, we need to get more info from our node manager to see what is starting the service and when it’s timing out and what is restarting it. We can do this by going to the following:
$GCINST_HOME\NodeManager\emnodemanager
Make a backup copy and then choose to edit the original nodemanager.properties file
By default, the loglevel=info
There are numerous log level settings:
- SEVERE (highest value)
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST (lowest value)
My recommendation is to set it to FINEST if you really want to log whats going on, but don’t leave it there, as it will produce a lot of logging and unless you are trouble-shooting something, there just isn’t any need for this amount of fine detail, so remember, a restart of the OMS service is required to update any change to the logging.
Update the loglevel info, save the file and restart the service. The data will be saved to the following file:
$GCINST_HOME\NodeManager\emnodemanager\nodemanager.log
To understand more about tracing and logging, see the Oracle Documentation that can take you through it, (as well as save me a lot of typing… :))
Trace and Log Files
em.start Tells you if there were any time outs and at what step the timeout occurred.
OracleManagementServer_EMGC_OMS1_1srvc.log This is the logged startup and shutdown of the actual service.
nodemanager.log This is the log of the nodemanager’s interaction with the OMS service.
EMGC_OMS1.out Steps of weblogic startup, java threads and times.
emctl.log Also shows timeouts set by emctl start process.
emoms_startup.trc Shows timeout by connections, (including sqlnet timeouts)
emoms_pbs.trc Shows actual timeouts at java level
There’s more data out there than this, especially if you use the EM Diagnostics kit, but just to start, it’s a good beginning.
Services
The OMS Service in Windows uses a standard naming convention, so it should look very similar to the one below:

Even though we are seeing one service, it can be controlled by many different daemons to ensure it is always running, as well as managing how long it has before timing out when it starts and restart options.
1. Service Timeouts:
There are two in the registry, depending on the version of Windows server that you have. These are here to assist you, but due to redundancy, they could impact you as well. These two values control how long to wait for a service to start before timing out and how long to before killing a service or if unresponsive to kill.
To see these, you will be working in the registry. The registry is the nervous system of the OS, so take great care when working with it and always make a backup of the folder you are working in before making any changes.
Click on Start –> Run Enter “Regedit” and click OK Go to Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control
Right click on the Control folder, choose export and save off the registry file as Services_TO.reg
In right hand “details” view and remove the following values, (either or both may be present) or even better, set them to a time that will allow enough time for the OMS to start before these come in and try to restart:
ServicesPipeTimeout
WaittoKillServicesTimeout
Remember, any changes you make here do not take effect until after you restart the computer. You can revert any changes by importing the saved registry file backup you made beforehand and performing another restart.
2. Auto restart of the OMS by the Node Manager
The node manager’s job is to ensure that the Windows Service is up and running for OMS. It is there check the OMS service and if it sees its down, restart it. If this is attempting to restart the OMS service while the registry setting are attempting to restart the OMS service, well, you are going to start seeing the issue here.
To stop Nodemanager from attempting to auto-restart service upon timeout:
Go to $GCINST_HOME/user_projects/domains/GCDomain/servers/EMGC_OMS1/data/nodemanager/startup.properties
Create backup of the startup.properties file and then open the file in an editor such as notepad or wordpad:
go to the following line: AutoRestart=true
Change value to “false”
Save the changes and the node manager will no longer attempt to autorestart the service if it sees it down once restarted.
3. Clustered services added to a failover, Oracle Failsafe or other clustering process, (not RAC).
Clustering, at an OS level is primarily for high availability, so redundant checks and restart options are built in everywhere for Windows services added. In the example of a failover cluster, the OMS service is added to the failover node.
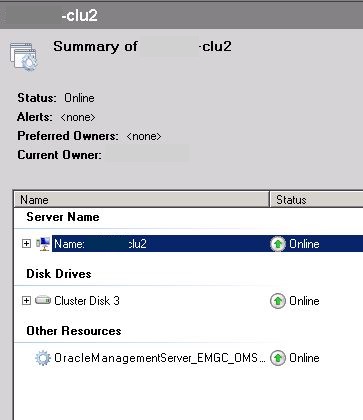
This allows for it to automatically fail over with the shared Virtual server and shared storage to the passive node and start up if there is a failure. The clu2 Virtual server has policy settings telling the OS what to do in case of failure and how to restart. This, by default is applied to all dependent resources and shared storage allocated to it.
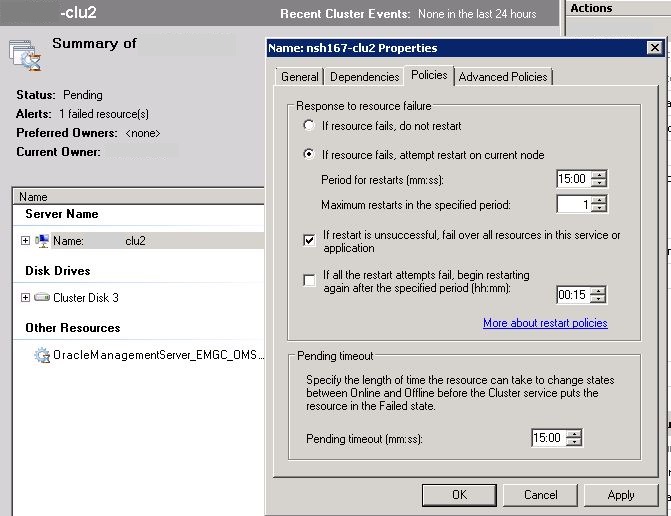
As you can see in the clu2 properties, the policies have been set if:
- A failure occurs, restart services and storage on the original active node.
- If the restart fails, then failover to the passive node.
- If the service or resource doesn’t start within 15 minutes, timeout.
You’ll also notice there is an option to not restart, as well as how soon a restart should be attempted.
You can update this at the server level properties, which will automatically propagate to the dependent resources, (it is the master of all policy settings, so you should set them here.)
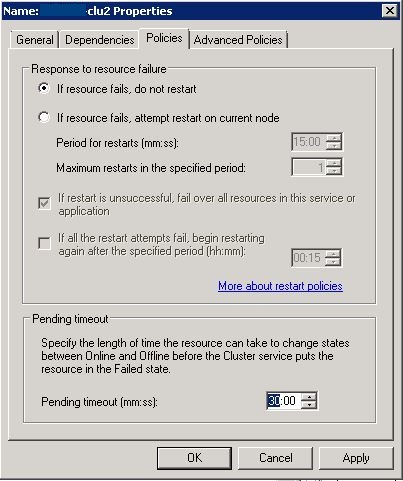
We have now asked in case of failure, do not restart and don’t timeout for 30 minutes.
Summary
I’ve shown you all the redundant settings that have been built in to ensure that the service is restarted and how long it can attempt to start before timing out and if it should restart and how long between restarts. The key to all this is knowing that only ONE should be managing this. If you decide to let Oracle manage it, then use the Node Manager settings and disable option 1 and 3. If you decide to let Microsoft handle it at the Service level, then disable 2 and 3 and so on.
Understand that if they are all left to manage on top of each other, you will have one timing out the start up while the another is still attempting to start and another notes it’s down and issues a restart. If you wonder why it’s taking 15 minutes or more to start your OMS on Windows, I’ll bet money you trace out the session and you’ll find more than one process attempting to start or restart the poor thing in your logs.
Honesty dictates that we shouldn’t just blame a complex issue on any one contributor and realize that with added complexity comes the need for added skills to ensure that you have the best configuration to support the technology. Taking the time to trace out and understand the issue will help make that happen.