
Delphix focuses on virtualizing non-production environments, easing the pressure on DBAs, resources and budget, but there is a second use case for product that we don’t discuss nearly enough.
Protection from data loss.
Jamie Pope, one of the great guys that works in our pre-sales engineering group, sent Adam and I an article on one of those situations that makes any DBA, (or an entire business, for that matters) cringe. GitLab.com was performing some simple maintenance and someone deleted the wrong directory, removing over 300G of production data from their system. It appears they were first going to use PostgreSQL “vacuum” feature to clean up the database, but decided they had extra time to clean up some directories and that’s where it all went wrong. To complicate matters, the onsite backups had failed, so they had to go to offsite ones, (and every reader moans…)
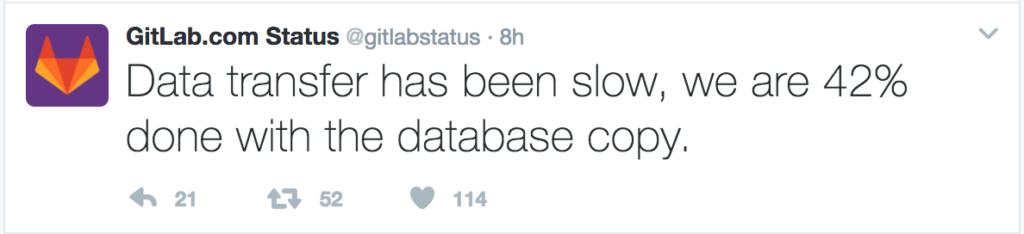
Even this morning, you can view the tweets of the status for the database copy and feel the pain of this organization as they try to put right the simple mistake.
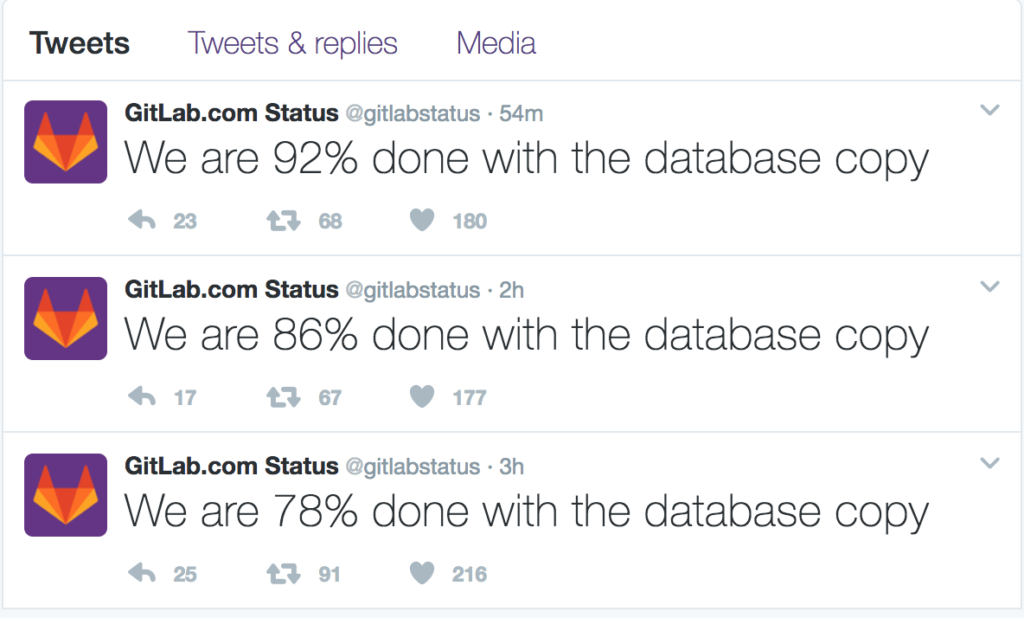
Users are down as they work to get the system back up. Just getting the data copied before they’re able to perform the restore is painful and as a DBA, I feel for the folks involved:
How could Delphix have saved the day for GitLab? Virtual databases, (VDBs) are read/write copies and derived from a recovered image that is compressed, duplicates removed and then kept in a state of perpetual recovery having the transactional data applied in a specific interval, (commonly once every 24 hrs) to the Delphix Engine source. We support a large number of database platforms, (Oracle, SQL Server, Sybase, SAP, etc) and are able to virtualize the applications that are connected to them, too. The interval of how often we update the Delphix Engine source is configurable, so depending on network and resources, this interval can be decreased to apply more often, depending on how up to date the VDBs need to be vs. production.
With this technology, we’ve come into a number of situations where customers suffered a cataclysmic failure situation in production. While traditionally, they would be dependent upon a full recovery from a physical backup via tape, (which might be offsite) or scrambling to even find a backup that fit within a backup to tape window, they suddenly discovered that Delphix could spin up a brand new virtual database with the last refresh before the incident from the Delphix source and then use a number of viable options to get them up and running quickly.
- Switch the users and application to point to the new VDB that was recovered to the point in time, (PIT) before the incident occurred. Meanwhile, IT is able to take their time recovering the production database with the physical backup, with little outage to the business.
- Create a VDB to the PIT before the failure and then create a connection between the production and the VDB, making a copy back to production of the data that was lost.
- If there was dire loss, (i.e. disk, etc.) create a VDB to the PIT before the failure and perform what’s called a V2P, or virtual to physical, rehydrating the virtual data to become the new physical database.
This is the type of situation happens more often then we’d like to admit. Many times resources have been working long shifts and make a mistake due to exhaustion, other times someone unfamiliar and with access to something they shouldn’t simply make a dire mistake, but these things happen and this is why DBAs are always requesting two or three methods of backups. We learn quite quickly we’re only as good as our last backup and if we can’t protect the data, well, we won’t have a job for very long.
Interested in testing it out for yourself? We have a really cool free Delphix trial via Amazon cloud that uses your AWS account. There’s a source host and databases, along with a virtual host and databases, so you can create VDBs, blow away tables, recovery via a VDB, create a V2P, (virtual to physical) all on your own.