
I love questions- They give me something to write about that I don’t have to come up with from my experience or challenges…:)
So in my last post, Paul asked:
I am not sure what happens to the other changes which happened while the release was happening? Presumably they are also lost? Presumably the database has to go down while the data is reverted?

The Setup
In our scenario to answer this question, I’m going to perform the following on the VEmp_826 virtualized database:
- Add a table
- Add an index
- Include transactions, both inserts and deletes
- Rewind the database using the Admin Console
As I’m about to make these changes to my database, I take a snapshot which is then displayed in the Delphix Admin console using the “Camera” icon in the Configuration pane.
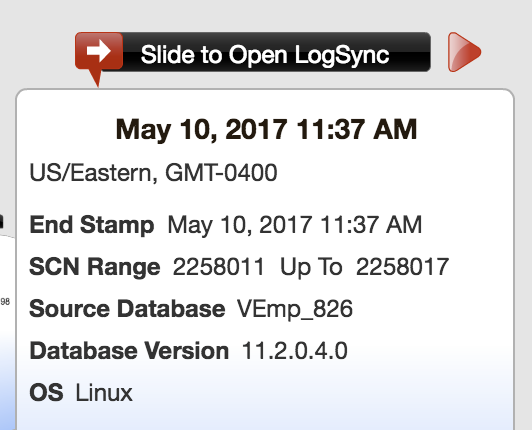
Note the SNC Range listing on each of them. Those are the SCNs available in that snapshot and the timestamp is listed, as well.
Now I log into my target host that the VDB resides on. Even though this is hosted on AWS, it really is no different for me than logging into any remote box. I set my environment and log in as the schema owner to perform the tasks we’ve listed above.
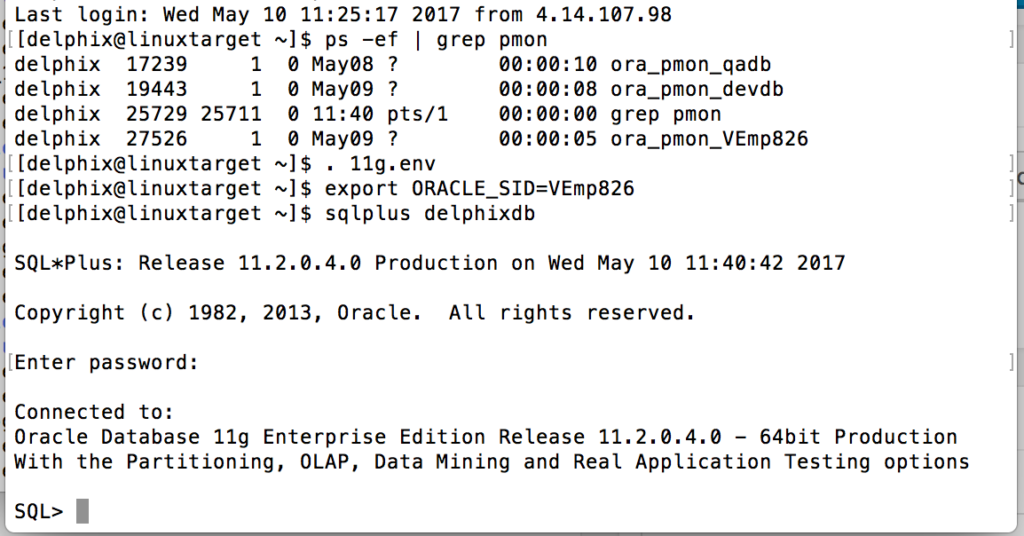
Create Table
So we’ll create a table, index and some support objects for our test:
CREATE TABLE REW_TST ( C1 NUMBER NOT NULL ,C2 VARCHAR2(255) ,CDATE TIMESTAMP ); CREATE INDEX PK_INX_RT ON REW_TST (C1); CREATE SEQUENCE RT_SEQ START WITH 1; CREATE OR REPLACE TRIGGER RW_BIR BEFORE INSERT ON REW_TST FOR EACH ROW BEGIN SELECT C1_SEQ.NEXTVAL INTO :new.C1 FROM DUAL; END; /
Now that it’s all created, we’ll take ANOTHER snapshot.
Add Data to Kinder Table
This snapshot takes just a couple seconds and is about 10 minutes after our first one and contains the changes that were made to the database since we took the initial change.
Now I’ll add a couple rows from another transaction into the KINDER_TBL from yesterday:
INSERT INTO KINDER_TBL
VALUES (1,dbms_random.string('A', 200), SYSDATE);
INSERT INTO KINDER_TBL
VALUES (2,dbms_random.string('B', 200), SYSDATE);
INSERT INTO KINDER_TBL
VALUES (3,dbms_random.string('C', 200), SYSDATE);
INSERT INTO KINDER_TBL
VALUES (4,dbms_random.string('D', 200), SYSDATE);
INSERT INTO KINDER_TBL
VALUES (5,dbms_random.string('E', 200), SYSDATE);
INSERT INTO KINDER_TBL
VALUES (6, dbms_random.string('F', 200), SYSDATE);
INSERT INTO KINDER_TBL
VALUES (7,dbms_random.string('G', 200), SYSDATE);
COMMIT;
We’ll take another snapshot:
Add Data to the New Table
Now let’s add a ton of rows to the new table we’ve created:
SQL> Begin
For IDS in 1..10000
Loop
INSERT INTO REW_TST (C2)
VALUES (dbms_random.string('X', 200));
Commit;
End loop;
End;
/
And take another snapshot.
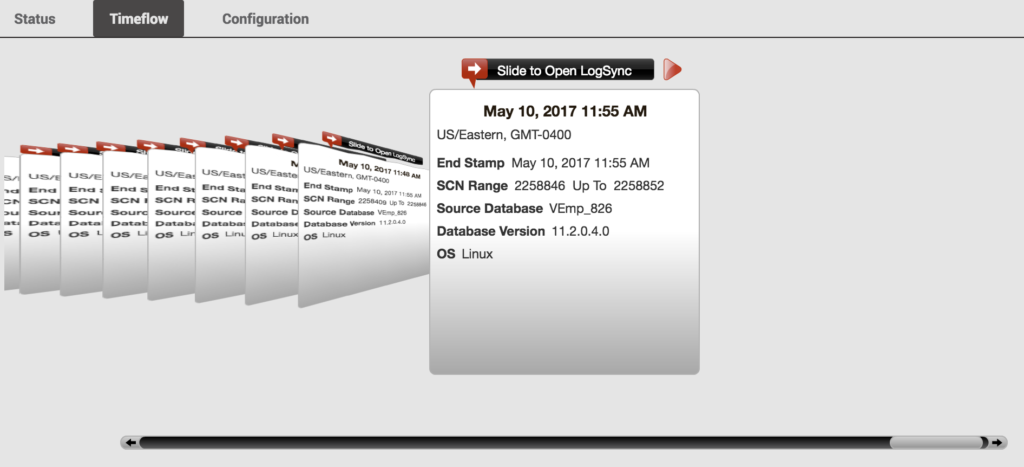
Now that I have all of my snapshots for the critical times in the release change, there is a secondary option that is available.
Snapshots at the DBA Level
As I pointed out earlier, there is a range of SCNs in each snapshot. Notice that I can now provision by time or SCN from the Admin Console:
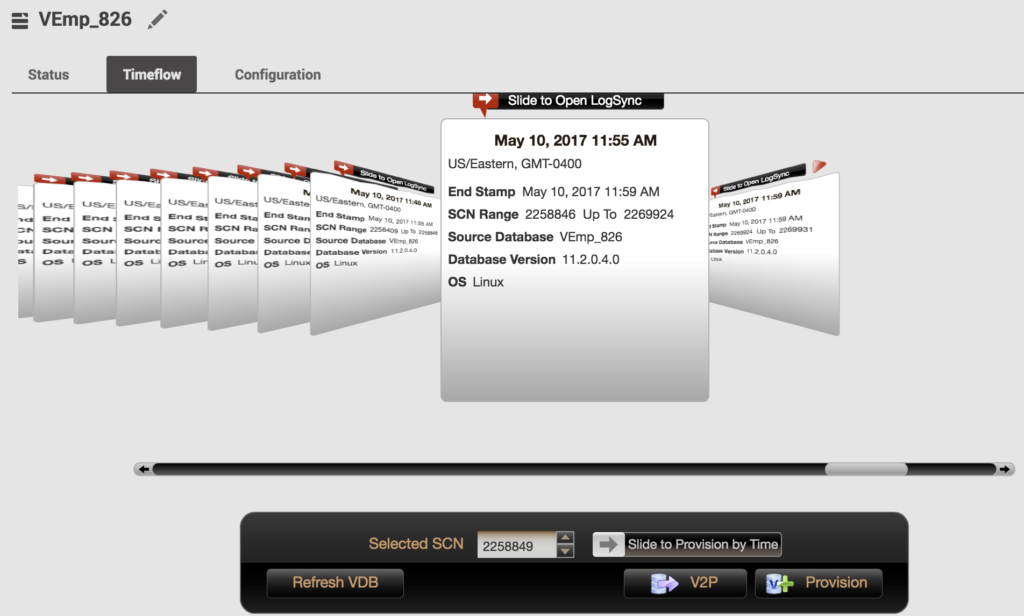
So I could easily go back to any of my SET beginning or ending SCN by the snapshot OR I could click on the up/down arrows or type the exact SCN I want to pinpoint for the recovery. Once I’ve decided on the correct SCN to recover to, then click on Refresh VDB and it will go to that SCN, just like doing a recovery via RMAN, but instead of having to type out the commands and the time constraints, this would be an incredibly quick recovery.
Notice that I can go back to any of my snapshots, too. For the purpose of this test, we’re going to go back to just before I added the data to the new table by clicking on the Selected SCN and clicking Rewind VDB.
Note that now this is the final snapshot shown in the system, no longer displaying the one that was taken after we inserted the 10K rows into REW_TST.
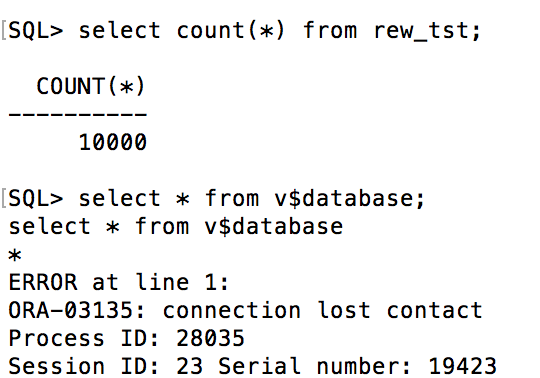
If we look at our SQL*Plus connection to the database, we’ll see that it’s no longer connected from our 10K row check on our new table:
And if I connect back in, what do I have for my data in the tables I worked on?
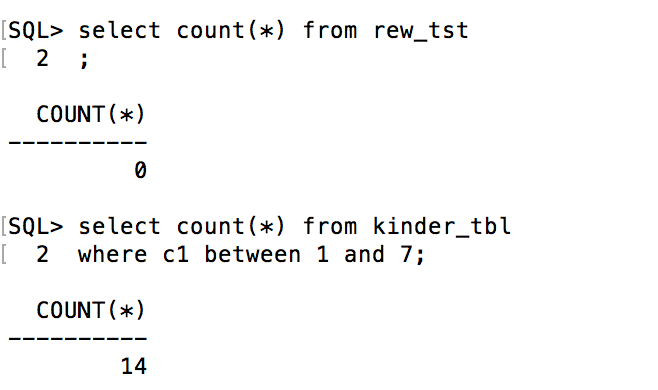
Pssst- there are fourteen rows instead of seven because I inserted another 7 yesterday when I created the table… 🙂
I think that answers a lot of the questions posed by Paul, but I’m going to jump in a little deeper on one-
Database Outage During a Rewind
Yes, the database did experience an outage as the VDB was put back to the point in time or SCN requested by the User Interface or Command line interface for Delphix. You can see this from querying the database:
SQL> select to_char(startup_time,'DD-MM-YYYY HH24:MI:SS') startup_time from v$instance; STARTUP_TIME ------------------- 10-05-2017 12:11:49
The entire database is restored back to this time and the Dsource, the database the VDB is sourced from and keeps track of everything going on in all VDBs, has pushed the database back, yet the snapshots from before this time exist, (tracked by the Delphix Engine.)
If you view the alert log for the VDB, you’ll also see the tail of the recovery steps, including our requested SCN:
alter database recover datafile list clear Completed: alter database recover datafile list clear alter database recover datafile list 1 , 2 , 3 , 4 Completed: alter database recover datafile list alter database recover if needed start until change 2258846 Media Recovery Start started logmerger process Parallel Media Recovery started with 2 slaves Wed May 10 12:11:05 2017 Recovery of Online Redo Log: Thread 1 Group 3 Seq 81 Reading mem 0 Mem# 0: /mnt/provision/VEmp_826/datafile/VEMP_826/onlinelog/o1_mf_3_dk3r6nho_.log Incomplete recovery applied all redo ever generated. Recovery completed through change 2258846 time 05/10/2017 11:55:30 Media Recovery Complete (VEmp826)
Any other changes around the change that you’re tracking from are impacted by a rewind, so if there are two developers working on the same database, they could impact each other, but with the small footprint of a VDB, why wouldn’t you just give them each their own VDB and merge the changes at the end of the development cycle? The glorious reasons for adoption virtualization technology is to have the ability to work in 2 week sprints and be more agile than our older, waterfall methods that are laden with problems.
Let me know if you have any more questions- I live for questions that offer me some incentive to go look at what’s going on under the covers!
Thanks for this – it is really useful
Hi thanks for the excellent blog post. I too am using Delphix, and I have just one question – is it normal for Delphix VDB rewind operations to take 6-8 minutes?
Mine is taking that long, and according to the Delphix job logs, the time consumers are (i) Recovering the Oracle database (1 min), (ii) opening the Oracle database (2.5 mins), (iii) Adding new online redo logs to VDB. My source VDB is fairly large, but I’d be surprised if this had anything to do with the VDB performance, since i’m only rewinding a few minutes in time.
Just wondering if this is the best that Delphix can do.
Hi David,
If the redo logs are large and the disk isn’t tier one storage, I could see this step taking a bit longer, (just as if you were creating redo logs on a physical database…) but I would add a trace and see what is taking so long. Hope this helps!
Kellyn