
Load testing as part of a cloud migration project is expected and should be built into the requirements. The goal is to set yourself up for success.

Log Latency
Recently I had a Cloud Solution Architect, (CSA) escalate an Oracle performance problem after migrating from on-prem to the cloud.
The information provided from the customer stated they were experiencing log sync latency in Oracle and that they hadn’t experienced this previously on-prem. They said there weren’t really any changes, just a simple lift and shift to Azure, so they were at a loss as to why the latency was being experienced. I was provided an AWR of the current environment, the user having taken manual snapshots for a 5 minute interval report. I was initially told they didn’t have an AWR from the previous environment for comparison which was challenging, but some times that’s how it is.
Big Jump
Upon review, I quickly noted that the database was Oracle 19c. This is the newest version of Oracle and when asked, they quickly admitted the database on-prem was an 11g RAC database and they had upgraded the database to 19c single instance for Azure. They didn’t realize this would make a huge difference and hadn’t realized this was no longer a simple lift and shift.
Lift and Shift, Strike 1: Upgrading from a very old release to very new release and had moved from RAC to single instance. Yeah, that’s a bit of a change.
This is something I would highly recommend you DON’T do. When doing a lift and shift to the cloud, you want the database version to stay as close to the same as possible to eliminate added challenges to the migration.
If a major upgrade is required, do it on-prem first and then lift and shift to the cloud, addressing any upgrade problems beforehand.
From 11g to 19c there were significant changes just to archive logging, including LGWR slaves and other features that were assuredly going to make a different outside of 100’s of other changes.
Code Blues
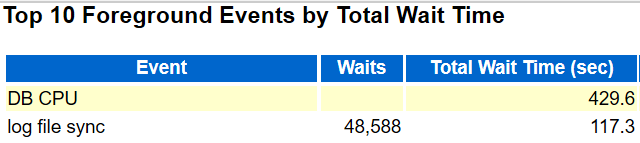
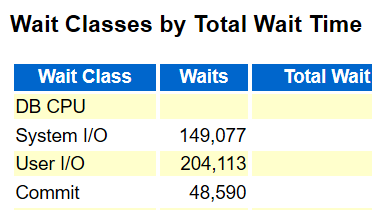
The next challenge that struck me about the workload from the AWR run in the 19c database was the amount of waits from commits.


I had nothing to compare it to, but the code logic built into the DML that I was observing, with the sheer quantity of single inserts and updates that had to be committed were going to create log syncing issues, but…the customer said the workload was the same as in their on-prem and they hadn’t had the problem there.
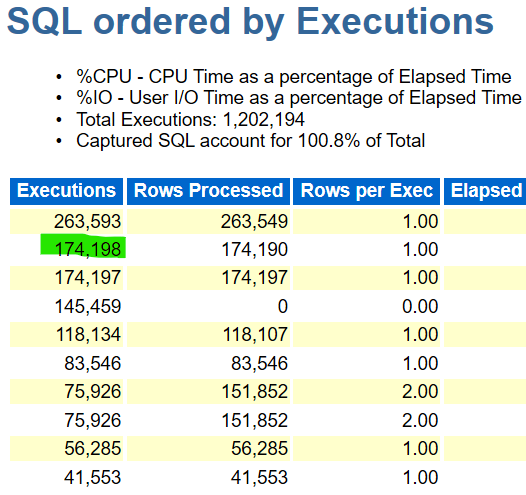
Now I’ve highlighted that second count on executions for a reason. It will all make sense in a moment and remember, this is a 5 minute workload in the database that was captured, so the number of executions is what transpired in 5 minutes.
AWR reports are pretty awesome, but they don’t have everything and commonly you would take the report, find the red flags and then investigate deeper into areas that cause you concern. After a review of the waits and the customer assuring me that the log syncs were not an issue on-prem, I directed my attention to the redo logs and disk they resided on, asking for:
- The sizes on the logs and were they located on a separate disk from the data.
- Information about the disk that the logs were residing on, (type, IOPS, size, etc.)
- Was read caching turned on the redo log disk
- Had they aslo added write accelerator on the redo log disk
Lift and Shift, Strike 2: Didn’t follow guidelines for Oracle VMs on Azure around redo logs.
All of recommendations either came back as yes or were able to addressed, improving the overall performance for the 19c database, but the claim they’d never experienced this type of log sync latency in the past, considering the code logic really troubled me.
Why Comparison Data is Important
Even though they were satisfied with the results of the changes, someone finally, located an older AWR report. Unlike the 5 minute report, the older report was for 45 minutes.
The first thing that it demonstrated is that log sync latency and commits were a problem before, just not as prevalent as they were in the 19c database:
I knew, whatever I was looking at for DML in this older, 11g report, it should have counts of 9 times higher in executions then multiplied by 4 for each of the RAC nodes it was scaled out to, than displayed in my 19c report.
Except….it didnt’:
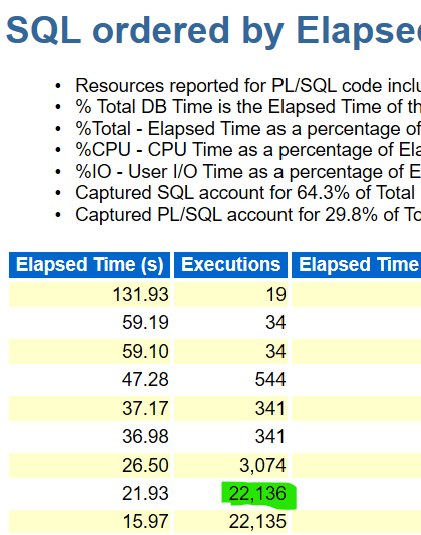
I had the other RAC node reports and the executions were similar to the first node, (just in case the workload was askew across the nodes, I wanted to verify).
So….If I took the executions for each node and calculated it down to a 5 minute execution window for this main statement:
(22136 + 22714 + 23528 + 23363) / 9 =10193 executions in 5 min
174198 in the 19c, which results in 17 times the workload of all the workload thrown at the original RAC environment on 11g on-prem.
Lift and Shift, Strike 3: The workload on the 19c environment was completely different than on-prem
When I brought this to the CSA and he asked the customer, discovered that they were just doing “load testing” against the environment and then escalated when they experienced the latency. The problem is, their code logic was the real reason the system couldn’t scale, not Oracle or Azure. We just ended up addressing it with the two latter platforms to workaround the software problem.
The reason they hadn’t experienced this in 11g or on-prem is that they’d never run the workload at this level before, but we have to ask, what was the purpose of this type of load testing?
Set Load Testing Up for Success
What do I mean by this? Some might think the job of load testing is to find out how much you can throw at the cloud environment you’ve built before it falls over. The truth is, this isn’t very helpful in the long run:
- It can be considerably time consuming and provides very little valuable information on a globally distributed infrastructure, which contains numerous layers of redundancy and a resilient interconnected network.
- It can create fake issues to trouble-shoot or escalate.
- Doesn’t provide you with real data about how your on-prem environment will perform in the cloud.
- It doesn’t prove that the cloud can’t handle it, it just means you didn’t add enough resources to handle the silly monstrosity you decided to run.
The goal of load testing should be to take a current snapshot of your workload, including peak requirements and run it against what you’ve architected to support your deployment.
Take the time to identify a real workload, or consider using Oracle database replay. It’s been around as part of Real Application Testing pack since 11g and is loved by many. It will allow you to take the SAME workload you run in your production system and duplicate everything in a new one without scrambling around trying to figure out what really changed.


