
I felt like playing with something new for the holidays and chose to investigate the Graph Database feature in SQL Server 2017.

Graph Database is no simple feature, so this is going to take more than one post, but we’ll start here and see how long it takes for me to be distracted by another new feature…:) As you can only have one user graph per database, that should limit my investigation to controlled chaos.
Graph databases are all about relationships- relationships between data. The output can provide insight into data that might not be apparent in a tabular fashion and the basic, graph data model is slightly different from how we think of a database model:
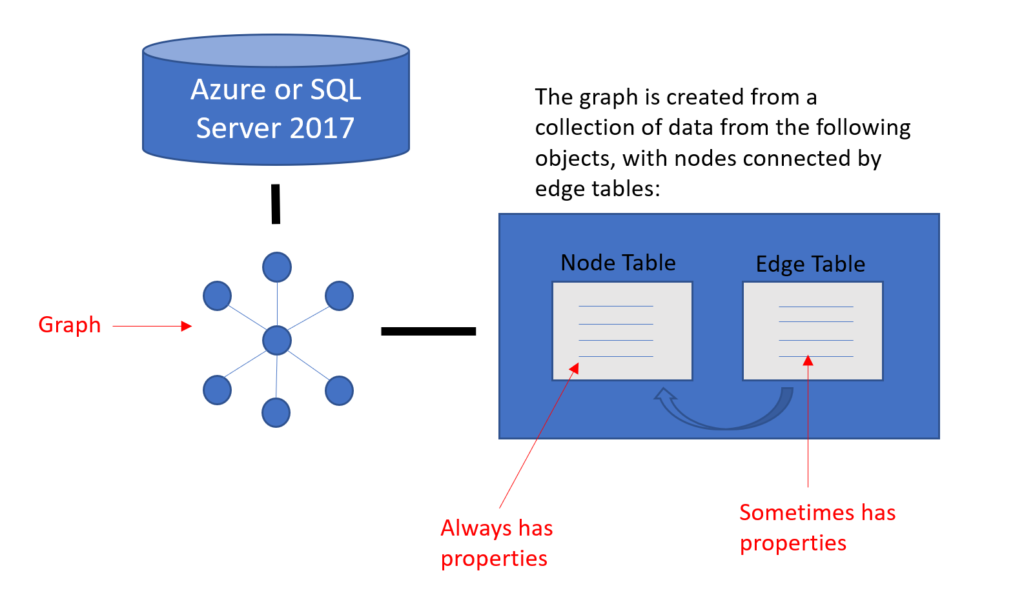
The first thing is to know that the feature is available in both Azure SQL Database and SQL Server 2017 as shown above, it’s comprised of node and edge tables.
You can quickly locate the graph database objects in a SQL Server 2017 database by querying sys.tables:
SELECT NAME as table_name, is_node as node_table, is_edge as edge_table FROM sys.tables WHERE IS_NODE=1 or IS_EDGE=1 ORDER BY table_name; GO
As you’ll note, the where clause is searching for node, (vertices) and edge, (relationship) values of 1. And these are the two objects that create the graph database. Those edge tables are going to define the relationship between each of the node tables, which then will render your graphs to provide value to the output.
Querying a graph database requires the use of a new TSQL function, called MATCH(), which then will then graph out the entities to the screen, matching up each node via appropriate edge for other node’s properties and attributes. When data is complex and the need for a more visual output to view the data in a non-tabular form, a graph database output can provide incredible value.
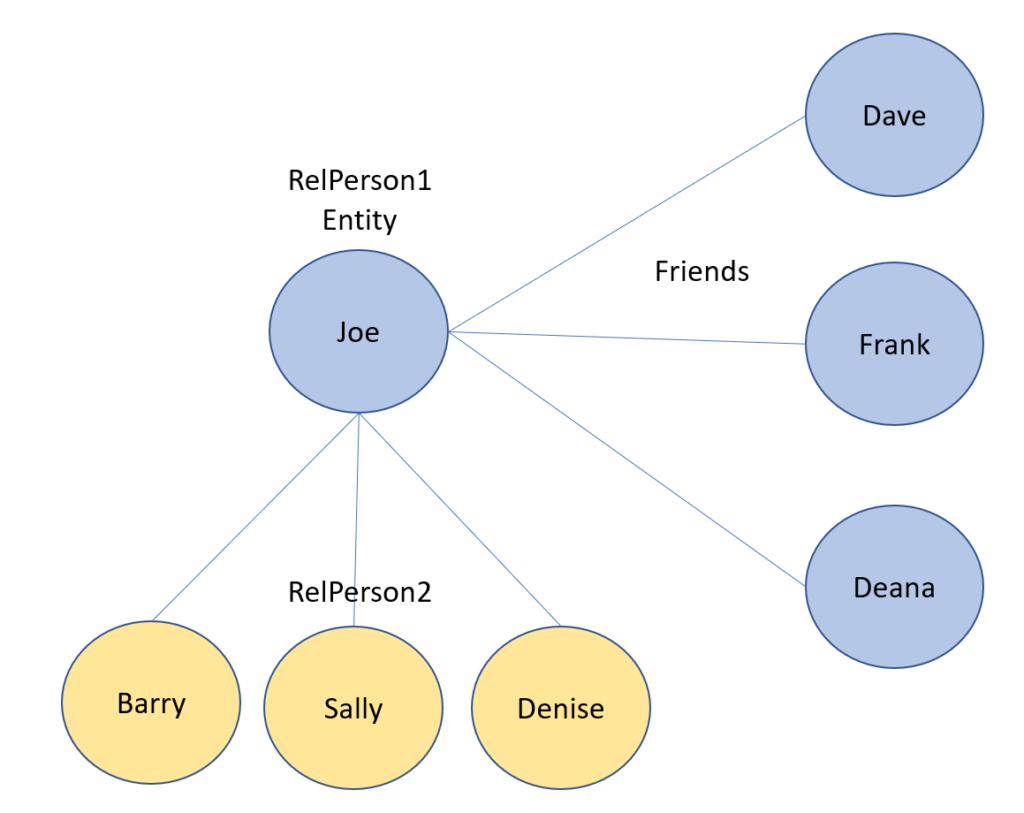
SELECT RelPerson2.Name FROM RelPerson1, Friends, RelPerson2 WHERE MATCH(RelPerson1-(Friends)->RelPerson2) AND RelPerson1.Name = 'Joe';
The physical relationship between all the people in this query that are connected to Joe might appear something like the following:
For the DBA, it’s important to know that node and edge tables can have indexes just like other tables, but most often are going to provide benefit on the those ID columns that connect node and edge tables, as that’s were the joins between the objects are made.
Where they differ is foreign keys. Outside processing and foreign keys aren’t required due to the design focus on relationships already present in a graph database.
I think the best examples I’ve seen of graph database use is for complex hierarchy, such as org charts and data centers. As the use of these grows and people find more value out of them, I have no doubt DBAs will be spending more time working with them.


