*Previously posted on the Microsoft Data Architecture Blog for the Tech Community.
An enterprise cloud, like Azure, handles an incredible variety of workloads and to be successful running Oracle in Azure means you need to know what you’re doing and where the sweet spot is for a relational workload.
I don’t want to get too deep here, as Azure Oracle SMEs are both data and infra, which is a hybrid area resulting in us splitting between the two focuses.
The Oracle Must-Knows
An Oracle database is a complex relational database, but there are terminology and physical architecture that is important to know before we proceed into this post:
- Database instance, (background processes)
- Memory, (SGA/PGA)
- Control files
- Datafiles
- Redo log files
- Archive logs
We’re going to discuss a common performance challenge when coming to the cloud and that’s around REDO LOGS. Oracle redo logs are the equivalent in Microsoft databases to the transaction log. Unlike SQL Server, Oracle has multiple logs that are part of the database that it switches between active, non-active and archiving. All operations that modify are written to the redo log buffer and then the log writer (LGWR) writes it to the active redo log. It’s not uncommon for the fastest storage IO to be required for the redo logs vs. datafiles because of this demand.
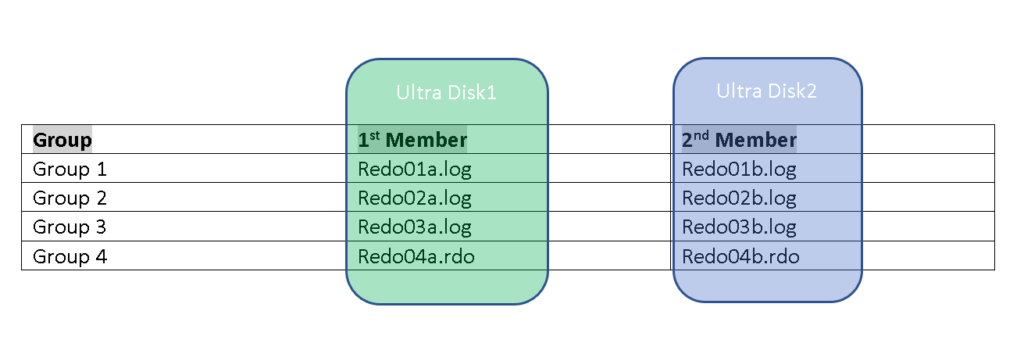
Redo logs are commonly mirrored to protect any changes not written to the datafiles and/or from a physical removal of one redo log “member” from a redo log member group.
| Group | 1st Member | 2nd Member |
| Group 1 | Redo01a.log | Redo01b.log |
| Group 2 | Redo02a.log | Redo02b.log |
| Group 3 | Redo03a.log | Redo03b.log |
| Group 4 | Redo04a.rdo | Redo04b.rdo |
Table 1
Notice that the extension can be anything you want- .log or. rdo is most common.
Oracle Wait Events
For Oracle, wait events are metrics that provide information about what is causing latency in performance of an Oracle workload. This information can be provided in multiple ways, but most often it is provided by the following:
- An Automatic Workload Repository (AWR) Active Session History (ASH) or Statspack report
- A query of top waits in Oracle
- A trace file or trace file TKPROF report
There are two main wait events that we see for Oracle databases:
- Log File Sync
- Log File Parallel Write
A report showing this type of latency would look like this:
Top 5 Timed Events Avg %Total
~~~~~~~~~~~~~~~~~~ wait Call
Event Waits Time (s) (ms) DBTime
—————————– ———— ———– —— ——
CPU time 5,099 41.0
log file sync 621,615 3,520 6 28.3
log file parallel write 575,295 2,573 4 20.7
For the example above, we expect CPU time to be the top consumer- CPU is on or off and for a database, we expect the usage to be high and Oracle has included the “wait for CPU” in the total, too, so again, it’s not surprising that it’s #1. I commonly look for those wait events that have over a 10% of DB time. In the example, log file sync is 28% and log file parallel write is almost 21%. The two waits together are 49% of the database time consumption. Fix these two waits and the database performance will significantly improve.
What is Log File Sync
As changes happen in the Oracle database, changes are written to the redo log. Once changes are committed or rolledback, the LGWR will then write what is in the redo buffer to the redo log that is active. Before the process is considered complete, a confirmation has to be sent back and this latency is what is referred to as log file sync or the time required to flush the log buffer to disk and writes confirmed. To address this type of wait event, optimization of the code can be performed or to physically address it, faster storage for the redo can be recommended.
What is Log File Parallel Write
An Oracle database will have at least three redo logs and if the DBA wants to mirror those redo logs, that means each redo log has been mirrored and placed in a group. This results in all writes having to be done twice from the changes in the database. As shown in table 1, the database could have two or more, (older days we saw more than 2 redo log members per group) that are being written to each time a write is performed. This is another area where faster disk, (write faster) or optimized code, (write less and less often) can remove latency.
Ultra Disk to the rescue
Ultra disk is a managed disk with configurable IO that the customer pays for depending on the IO demand. For a large Oracle database, it rarely makes sense for datafiles due to the cost, but for redo logs, the size is small and the ability to configure the IO specifically for the high write needs can make a huge difference for the wait events discussed in this blog post.
Calculate the needs of the log files using the IO STAT FUNCTION SUMMARY in the AWR report, which will tell you the number of MBPs/IO Requests that are needed to meet demand. Pad a little over this to address averages in the report and this should give you the values to target for:
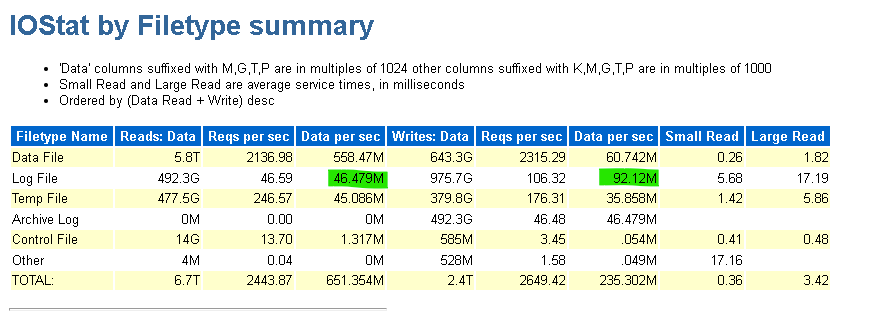
Using this information, along with the size of your redo logs, you can then price out ultra efficiently and pay for what you need:
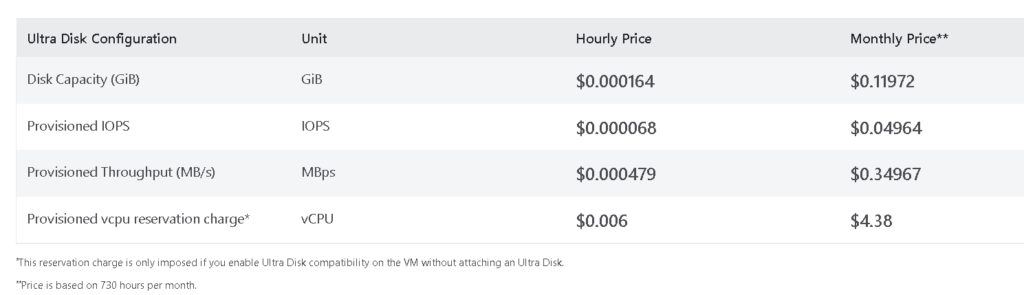
If you only have a Log File Sync issue, then a single ultra disk and moving the redo logs to this new disk can address this problem. If you have both Log File Sync and Log File Parallel Write, then allocate TWO ultra disks, moving the 1st members of each group to one ultra disk and the 2nd members of each redo log group to the second ultra disk: