
*Previously posted on the Microsoft Tech Community Data Architecture Blog, (consolidated from two blogs posts)
One of the biggest challenges to IO demands on an Oracle on Azure VM is when customers continue to utilize streaming backup technology like RMAN or import/exports via DataPump in the cloud. Although it shouldn’t come as a surprise, these two technologies can often be the biggest consumers of IO- more than overall batch or transactional processing.
One of the reasons customers migrate to the cloud is the benefit to share infrastructure resources and features at a lower cost, but with sharing those resources, no one wants to be the noisy neighbor. Azure, as with other cloud providers, ensures that a VM can’t be the noisy neighbor by spreading workloads for a VM across hardware and setting limits per VM series and size.
Heavy Cost of Archaic Backups
With this understanding, it is important to know that backups, both physical and logical, can be the main contributor to IO throttling on a VM. When this occurs, the workload has hit the threshold for how much IO is allowed, either for storage or network and latency occurs. One of the best ways to avoid this is to rethink how we backup up Oracle VMs in the cloud.
Snapshots can be a powerful tool and many organizations have already embraced this technology, but if you have not, there are definite benefits:
- Extensively less IO requirements to take a storage level snapshot.
- Faster Recovery times.
- Simpler cloning process for databases and multi-tier environments.
- A cost-effective backup solution since storage snapshots are inherently incremental.
Azure Backup Snapshots for Oracle
This brings me to Azure Backups private preview for Oracle snapshots. For those customers who want a single pane of glass for their backups, you can now use the same Azure backup for your Oracle databases running on IaaS VMs just as you do for other Azure cloud services.
Azure Backup for Oracle works with Oracle, setting the environment, quiescing the database, taking a snapshot and then releasing the database, to then complete the rest of its work behind the scenes. The workflow for the backup pre-script/snapshot/post-script is as follows:
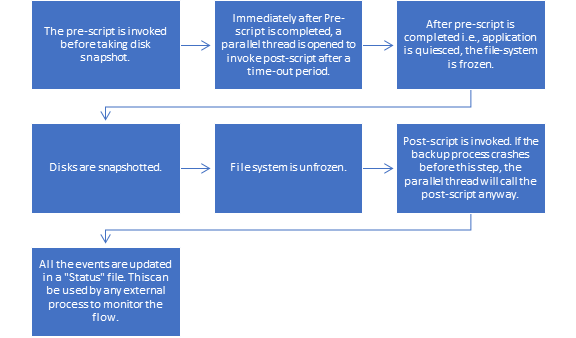
Snapshots can be configured on a daily basis or more often, but recognize that while the volume is restored to the time of the snapshot, the database remains in a recovery state and can be rolled forward using the RECOVER AUTOMATIC DATABASE with archive logs to any point in time to eliminate data loss. If just using the snapshot to refresh a development or test environment, a snapshot recovery can be done in a matter of minutes to the time of the snapshot, refreshing data without the extensive time or work that is required with more traditional methods of cloning.
Of course, this will require archive logs be copied with a custom solution to be used to recover if a Point in Time, (PiT) recovery is desired. I haven’t met a DBA yet who doesn’t have a shell script or other process to copy their archive logs to secondary storage to protect these valuable assets and with Azure snapshots for Oracle, this should be an additional step for anyone wanting to do more than just recover from a snapshot of a volume. Most customers, depending on the amount and size of archive logs, choose to copy to blob, NFS or AFS. Without this secondary step, only the archive logs that existed at the time of the snapshot locally will exist for recovery purposes.
Options for Data Refreshes
For customers that have used Oracle Datapump for data refreshes, this often required a full export of the database performed on a regular basis, consuming significant resources on a cloud VM. With an Azure backup snapshot of the storage, a clone can be created and using this clone, an object copy can be performed instead of standard datapump export/import. This can also be used to perform a transportable tablespace import without the resource demands to preemptively export data every night from the database, freeing up resources for batch and transaction processing.
With this shift, there is less worry about having to scale up a VM unless its for right reasons- like due to data acquisition or business and revenue increase. Costs are decreased on the storage side that were once used by physical datafile copies in exchange for snapshots, which on average use considerably less storage space. When focusing on Oracle, backup storage can be important as these databases are often some of the largest in the relational database world.
Where We Are Today
Due to this, the Azure Backup product team and the Oracle CAE team banded together to design, code and finalize a solution that provides volume snapshots for an Oracle database running on managed disk or Azure NetApp Files, (ANF) in any Azure VM. As with other snapshot solutions, this doesn’t work for Ultra Disk, but as we recommend using Ultra for redo logs, (it’s too often limited in features and cost prohibitive to put datafiles in Ultra) It’s easy to limit the use of Ultra Disk to RMAN for backing up the redo logs and then use these subsequent archive logs, stored on a secondary storage, such as Azure shared files standard share mounted to the VM to provide the Point in Time recovery after a volume snapshot has been recovered. Azure shared files is recommended over other storage options due to the backup design, ensuring that they can easily be recovered if needed from an automated storage backup.
Azure Backup Volume Snapshots for Oracle provides a recovery solution option for Oracle to secondary or primary VMs to restore the snapshot, then apply the archive logs via RMAN, post the restoration. This removes the heavy IO consumption of nightly full or incremental backups of the database and only changes from the archive logs will need to use RMAN.
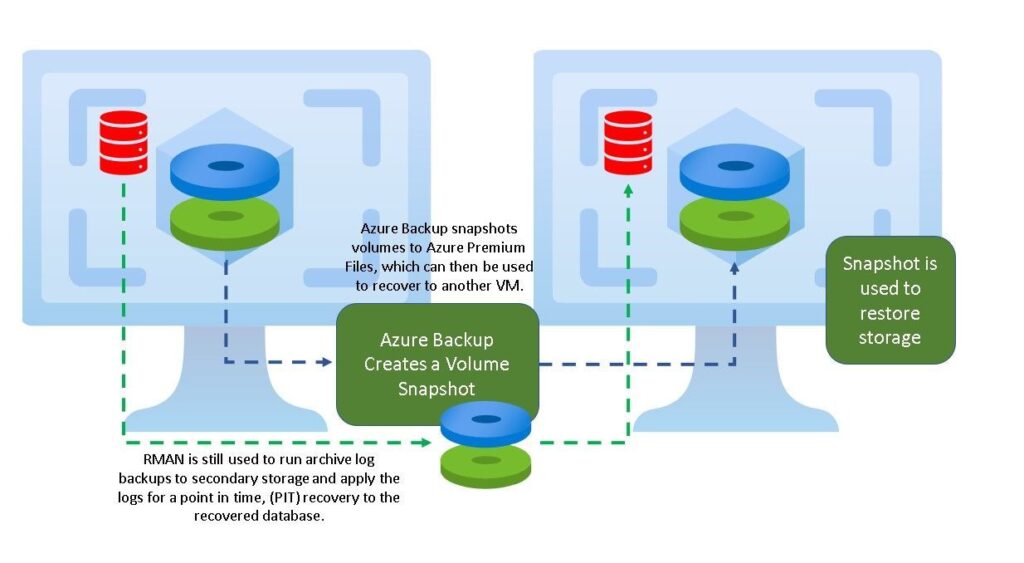
The process for the scripted process will perform the following:
- Locate the backupdba OS group on the VM
- Create an azbackup OS account on the VM
- Setup an Azure Files share to use with the archive logs
- Create the ops$azbackup database account inside the Oracle database
- The backup script will redirect the archive logs to the Azure File share created in step #3
- Set the parameter for the ARCHIVE_LAG_TARGET in the database to be backed up
Once this is completed, then the initial backup is performed and an update needs to be made in the /etc/azure/workload.conf configuration file.
At this same time, an application tier backup job to be consistent with the database tier should be performed for recovery synchronization.
If you’re interested in using Azure Backup Volume Snapshots for Oracle, check out the pre and postscripts, which can be found in the Github repository here:


