
*Previously Posted on the Microsoft Tech Community Data Architecture Blog
If you’re migrating your data estate to Azure, as is normal considering Azure is an enterprise cloud that can be the home for all data, including Oracle, you may wonder what storage solutions there are to support these types of IO heavy workloads. Maybe you didn’t realize how important storage was to Oracle in the cloud. Most customers we word with are focused on what vCPU and memory are available in Azure, but for 95% of Oracle workloads, it’s IO that makes the decision on the infrastructure we choose and of that IO, its throughput, (MBPs) that is most often the deciding factor in the final VM sizes and storage type.
This post isn’t going to be about promoting one storage vendor or any solution over another, but hopefully help you understand that each customer engagement is different and that there is a solution for everyone, and you can build out what you need and meet every IO workload with Oracle, (or any other heavy IO workload) in Azure.
There are limits on storage, but more importantly, there are limits per each VM on storage and Network that must be considered. When choosing a VM, don’t just match the amount of vCPU and memory, but can the VM handle the throughput demands your workload will place on it. One of our favorite VMs types is the E-series ds v4. This sku series offers us the ability to have premium SSD for the OS disk, constrained vCPU versions if we need to have a larger “chassis” and memory with lesser vCPU for licensing constraints and higher throughput than we see with many others with similar configurations.
If you inspect the specifications by SKU size, you will see displayed the max cached IOPS/MBPs and Network bandwidth for the E ds v4 series:
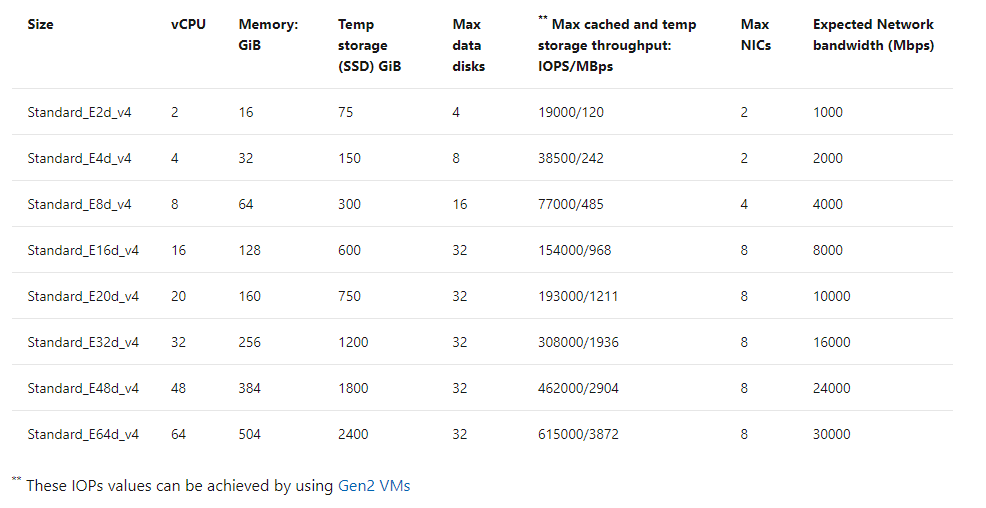
Table 1, E-series, ds v4 VMs in Azure specifications
The above table will result in both premium disk and ultra disk being held to both storage and network limits displayed, or for solutions such as ANF, Silk, Excelero or Flashgrid, we’re held to only the network limits shown. As I stated earlier that throughput, MBPs is the biggest headache, not IOPs, (i.e., the number of requests) you can understand why the latter solutions come in handy with IO heavy workloads such as Oracle in Azure.
If you have sized out the Oracle workload for Azure properly, then you will know what you require in Azure IaaS to run it and can then choose the best VM, and storage needed. If you’re then puzzled by storage solutions, let’s take a deeper look and especially for Exadata, demonstrate what options there are.
Don’t Guess
I can’t stress enough, if you haven’t sized out the Oracle workload from an AWR that shows considerable database workload activity from the customer’s environment, you’re just guessing. Do NOT try to lift and shift the infrastructure, especially from an Exadata- you are AGAIN, wasting your time. An Exadata is an engineered system and there are infrastructure components that can’t be shifted over and more often is quite over-provisioned.
I also run into pushback on going through the sizing exercise. Many will want to simply take the existing hardware and lift and shift it to the cloud. This is one of the quickest ways to pay two or more times for Oracle licensing. I’m not going to argue with sales people who pushback with me on this, but chalk the deal or migration up as lost and go spend my time on a migration that’s going to be successful from the beginning.
Fight Me
So I know what the documentation says for storage IaaS VMs–
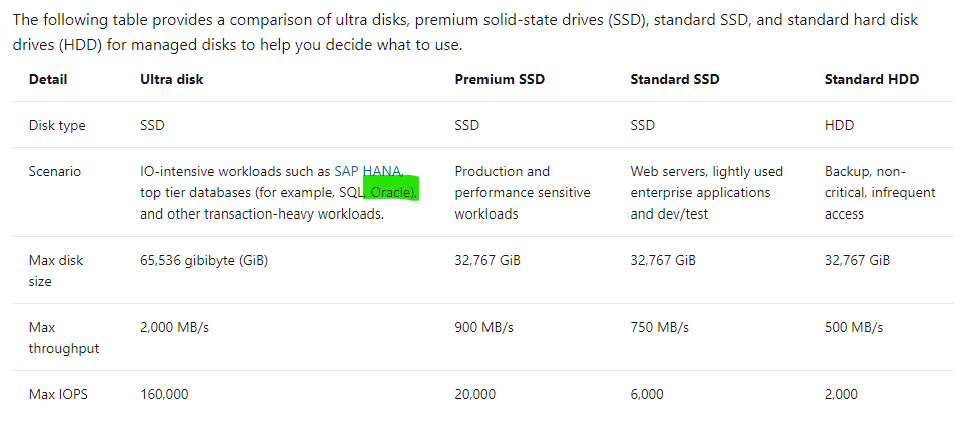
Table 2, Storage Options for IaaS VMs in Microsoft Docs.
Reality of what is best for Oracle on Azure may not agree with what is in this table and I’m going to tell you now, I don’t agree with the above table. Ultra disk may look appealing for Oracle, but we simply haven’t found the limitations vs. the cost for Oracle worthy, where for other uses, such as redo logs, it’s a fantastic win, (along with non-Oracle opportunities.) Ultra is still limited by the storage and network limit per VM, and this means that we can’t gain the throughput that we require for most heavy Oracle workloads with 2000+ MBPs.
Using example workloads, I can begin to direct and “evolve” our storage solution and the levels we use with real customer use cases:
| Storage Name | Storage Type | Use |
| Standard HDD | Native | Not for use with Relational Databases |
| Standard SSD | Native | Less than acceptable for Oracle workloads or Oracle VM OS Disks |
| Premium SSD | Native | Standard Oracle Workloads and OS Disk, With Datafiles, always turn on ReadOnly host caching. |
| Ultra Disk | Native | Redo Logs, rarely for datafiles due to limitations. |
| Azure NetApp Files | Native with 1st Party Partnership | High IO Oracle Workloads, some Exadata |
| Silk | Third Party Partnership | High IO Oracle + Workloads, especially Exadata |
| Excelero NVMesh | Third Party Partnership | High IO Oracle + Workloads |
| Flashgrid Storage Fabric SW | Third Party Partnership | High IO Oracle + Workloads |
| NetApp Cloud Volume OnTap (CVO) | Third Party Partnership | High IO Oracle + Workloads, especially Exadata |
Table 3, Storage options most common for Oracle in Azure
As you look at the table above, you realize that there are a few options at the lower IO workload levels and many at the higher ones. This is where knowledge of your workload and demands, along with unique features of each will come in handy when deciding.
Premium Disk
It is going to be very, very rare day that we place an Oracle workload on standard SSD. A P10 disk will be recommended practice for the OS Disk for each VM Oracle will be running on and then we need to start allocating storage for the datafiles, redo logs, etc.
We rarely, if ever come across Oracle databases that don’t need the IO horsepower for anything but Premium. With that, we get significant performance gain from ReadOnly host caching so the P40/P50, (minus that last 1Gb to leave it inside the limit for ReadOnly host caching of 4095 TiB) disks are our favorite and meet the needs of many Oracle workloads. For the smallest Oracle database workloads, we may use smaller premium SSD or stripe premium disk, as we can use multiple disks with a single ASM diskgroup. Always pay attention when choosing your VM size, there is a max number of data disks that can be attached, so this will also determine what storage you choose, (refer to table 1.)
ReadOnly host caching is only available on certain VM series/skus, as well as mid to high range premium SSD and limited to 4095 TiB. If you allocate a disk larger than that, the host caching will automatically be disabled. We hear a lot from Infra folks about “disk bursting”, either credit or On-demand versions with IO in Azure premium SSD storage. I haven’t had a customer workload that really could make use of it, but for smaller workloads, upwards of 30 minutes of bursting could be beneficial. For P40-P80, there is an unlimited bursting that can be an option at 1000 MBPs. Many customers batch loads in Oracle are just too intensive and too long to take advantage of credit-based bursting and On-demand or changing performance tier is too expensive or too inconsistent in performance for many. For relational database workloads, consistency in performance really is key. Most customers choose to stripe disks to get the max throughput from storage for most Oracle databases or choose higher tier storage, skipping bursting options all together.
Using the table below, you can see the size and the IO max for each premium storage, which tells you what you will be limited to for a single disk unless you stripe-
| Premium Disk Size | Storage Amount | IOPs Max/Bursting | MBPs Max/Bursting |
| P10 | 128 | 500/3500 | 100/170 |
| P20 | 256 | 1100/3500 | 125/170 |
| P30 | 512 | 2300/3500 | 150/170 |
| P40 | 1024 | 5000/30000 | 250/1000 |
| P50 | 2048 | 7500/30000 | 250/1000 |
| P60 | 8192 | 16000/30000 | 500/1000 |
| P70 | 16384 | 18000/30000 | 750/1000 |
| P80 | 32767 | 20000/30000 | 900/1000 |
When striping, again, you must be cognizant of the max number of disks you’re allowed per VM, remembering that the OS disk is counted as one.
Ultra Disk
We like Ultra disk, but it has numerous limitations when we start pricing out what it will take to run a database on it, realizing that it will be limited at the storage, not just the network limit per VM, that we have no volume snapshot mechanism or availability zone solution using it and the complicated pricing model, it ends up being a solution with limited use with Oracle. That use is redo logs when a database resides on premium disk and experiencing redo log latency.
More often a better option is to stripe premium disks to achieve upwards of 2000 MBPs, use Azure Backup volume snapshots to eliminate excess IO created by large RMAN backups and no need to spend more money on Ultra Disk.
Azure NetApp Files (ANF)
Many folks think this is a third-party solution, but it’s really a native solution in Azure in partnership with NetApp, and might need a rename to something like, “Azure Enterprise Files”. It’s a first tier storage for high IO workloads and is only limited by the network per VM. An ANF capacity pool is storage built at the region level, has HA built into the solution and can be allocated to multiple VMs, offering the ability to meet numerous workloads that other native solutions can’t. Along with robust cloning capabilities, shared volume snapshots across capacity pools even across regions, which can be used to bring up a second Oracle environment in a short order and avoid additional licensing that would be required if Oracle Data Guard was present.
ANF is also an excellent choice for datacenter migrations where a native storage solution is required or strict, Azure certified storage with high IO capabilities are needed.
Silk
As I work almost primarily on Exadata migrations, I spend a lot of time with Silk data pods. This is a third-party solution that uses a number of patented features to build out a Kubernetes data pod inside Azure, out of compute nodes, (D-series VMs) and management nodes, (L-series VMs) using the NVMe storage to accomplish fast IO. They have compression and dedupe that simplifies some of the additional “decoupling” I’d have to do with the loss of Hybrid Columnar Compression, (HCC) in Exadata. As the IO would grow considerably without HCC, I commonly use additional partitioning and Oracle Advanced Compression to try to make up for that loss.
Another feature that I love about Silk is it’s thin cloning. The ability to create a read/write clone and not have a storage cost is beneficial for E-Business Suite (EBS) and other Oracle applications that require consistent copies across multiple stage environments and the ability to save on storage while doing this, plus doing it quickly is fantastic. Anyone who’s used sparse clone on Exadata would love to have the thin clone in Silk, too.
The Rest
While both, like Silk, use VMs and the local storage to creation high IO solutions with the only per VM limitation at the Network layer, they don’t have some of the additional features such as compression/dedupe, thin cloning and volume snapshots. I’ve also been introduced to NetApp Cloud Volume OnTap,(CVO) which marries the best of onprem OnTap storage with Azure in a third-party solution that is closer in features to Silk and can benefit Exadata workloads that rely on HCC, thin cloning and snapshot backups.
The How
When deciding what solution to go through, it’s important to identify the following:
- The vCPU and memory requirements
- The IO, both IOPs and MBPs, especially the latter limit for the VM
- Using the size of the database, along with IOPS/MBPs, then choose the type of storage, (premium or high IO)
- The business’ SLA around Recovery Point Objective (RPO) and Recovery Time Objectcive (RTO) will tell you then which solution will be best that meets the IO needs.
- A secondary service can be added to create additional functionality, (as an example, we add Commvault to ANF to add additional cloning features at a low cost).
So let’s take a few example and look at what kind of combinations you might choose:
Example Oracle Workload #1
- 16 vCPU
- 128G of RAM
- IOPS 22K
- MBPs 212M
- DB Size: 5TB
- Backup Size: 23TB
- RPO/RTO of 15 min/8 hrs
I know this may seem limited on all that you might need to size it out, but we are assuming a sizing assessment has been done from an AWR and from this we can come up with the following recommendations:
Recommended VM: E16ds v4
Storage Option A
- 1 Premium P10- OS Disk
- 6 Premium P40 Disks- Datafiles and Redo Logs
- 24 TiB of Azure Blob Storage- Backups
- Backup strategy: RMAN
Storage Option B
- 1 Premium P10- OS Disk
- 5 Premium P40 Disks- Datafiles
- 40G Ultra Disk- Redo Logs
- 24 TiB of Azure Premium Blob Storage- Backups
- Backup Strategy: Azure Backup for Oracle
Example Oracle Workload #2
- 32 vCPU
- 480G RAM
- IOPs 100K
- MBPS 2800M
- DB Size 8TB
- Backup Size 28TB
- RPO/RTO of 15 min/2 hrs
Due to the limited RTO, I would use Oracle Data Guard to support the 2 hr RTO, as an RMAN recovery from storage wouldn’t meet the requirements for the DR on it’s own.
Recommended VM: E64-32ds v4 constrained vCPU VM
- 1 Premium P10- OS Disk
- Storage Option A: ANF with capacity pool and snapshot taken every 10 minutes to secondary capacity pool in separate region.
- Storage Option B: Excelero with Oracle Data Guard secondary in second Availability Zone, using Fast-start Failover and Observer/DG Broker and RMAN backups to Premium file storage.
Example Oracle Workload #3
- 16 vCPU
- 85G of Ram
- IOPs 300K
- MBPs 4500M
- DB Size 12T
- Backup Size: Using ZDLRS from Oracle
- RPO/RTO of 5 min/1 hr
- Using Exadata features HCC, smart scans, storage indexes, flash cache and flash logging
Recommended VM: E16ds v4, (extra memory will come in handy with the SGA and PGA grows post migration)
- 1 Premium P10- OS Disk
- Storage Option A: Silk with Data Guard, thin cloning, and volume snapshot and their compression/dedupe. Lessen post migration optimization that will need to be done.
- Storage Option B: ANF with Data Guard, volume snapshot for backups to eliminate some of the overhead of IO from RMAN, add Oracle advanced compression and partitioning, along with build out a partitioning strategy to assist with increased IO with loss of HCC.
With the examples above, I stuck to the E-series, ds v4 type VMs, as again, these are some of our favorite skus to work with Oracle on Azure in IaaS. Realize that we do have options for each type of workload, but that depending on the IO, there are different solutions that will meet the customer’s requirements and it’s important to have the right data.


