
In my last post, I discussed some of the unique challenges migrating Oracle workloads from Exadata to Azure posed. Engineered systems are not your everyday lift and shift and are rarely simple.

Although I covered some focus areas for success, I’d like to get into the migration philosophical questions around cell offloading and IO. cell information is referred to in the average Oracle 12c AWR report almost 350 times. That’s a LOT of data to consider when migrating a workload to a server that won’t have cell nodes to OFFLOAD TO.
If cell nodes are creating a ton of different IO in Exadata and don’t exist in Azure, will it require IO in Azure?
Its not far off from the old saying, “If a tree falls in the forest and no one is around to hear it, does it make a sound?”
Why yes, yes it will require IO and a lot of it.
Its one of the more interesting areas on the subject of calculating IO in preparation for migration to Azure from Exadata. Exadata offloads whenever it can- Many Exadata specialists shrink the SGA with the purpose of forcing an offload because Exadata was engineered to perform well when it does so- Why perform a task on the database nodes when you can force an offload and put a cell node to work? Sometimes this work is efficient and provides great value, other times, especially such as a “single cell block read”- isn’t. There’s also the question of the amount of IO produced and calculated by the offloading process itself.
The Power of the AWR Report
An AWR report breaks up this information in multiple parts and with subsequent versions of Exadata, AWR has been enhanced to provide us with more information about what part of an offloaded process creates IO.
The reader of the AWR should spend considerable time in the System Statistics section inspecting the cell IO breakdown. This is very valuable to discover, not only if the database workload is offloaded efficiently, (it’s an engineered system, not a miracle worker, so if the database design or code is not built to use Exadata features, don’t expect it to…)
What Isn’t Coming to Azure
With the migration to Azure, there are certain features that may not impact cell IO estimates like you might assume:
- Secondary cell nodes (servers)
- Flash cache
- Flash log
- RAC “shipping” between nodes
- Smart scans
- Storage Indexes
- HCC, (Compression)
Any of these processes need not only be identified by percent of IO workload, but estimates on what the post-migrated database will do without it.
Cell Nodes: Increases in scans on database nodes, needed increases in buffer cache, more activity between cluster nodes, (If RAC is retained). What we must take into consideration is how much IO is created just to produce an offload and when its no longer an available solution, how much IO may not occur.
Flash Cache: The removal of Flash level IO rated feature removed from the scenario has to be considered, but when sizing is being performed, you must determine how much of it and how often was it being used by the workload.
Flash Log: Greater latency on the logwriter, (LGWR) writes. These number often impact if I’m going to implement an ultra disk solution to house the redo logs.
RAC Shipping: Without cell nodes directly returning results to a node, all shipping of results will need to be shipped between nodes with all work being performed on the database nodes.
Smart Scans: Increase in IO if buffer cache isn’t increased significantly and without cell nodes, great IO for those scans that still exist.
Storage Indexes: These indexes only exist in memory- without them being manually created, poor performance and increased IO must be expected. A full assessment of what storage indexes exist and to ensure they exist in the migrated system is a must.
Hybrid Columnar Compression (HCC): This allows not only for highly compressed storage, but ability to read from compressed blocks, saving considerable IO.
Cell Data Breakdown
System statistics in the AWR report provide us a detailed wait report, broken down by statistics vs. just wait type or category. One of the areas broken down in the report is cell usage, which for this post, is where we will focus on.
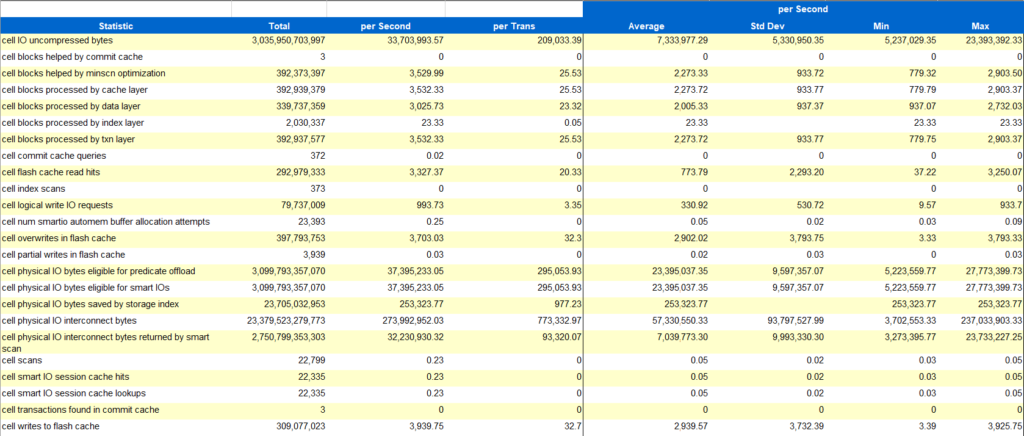
**All data presented in this post has been masked. Thanks for playing.
Let’s spend some time looking over some of these values and what they mean to someone migrating a database from Exadata onto Azure.
There’s a math to all of this when calculating the IO to figure out what needs to be considered and what shouldn’t. Some of it is exact science and then, with a bigger picture taken into consideration, a bit of an art, too.
cell IO uncompressed byte: Total IO that was returned in smart scans/offloading, with decompression by the cell nodes after storage index filtering and other optimization. This is the natural number that is used for IO considerations for migrations, but we need to keep a few things in mind:
- With an expectation to raise the SGA, there will be less table scans, which will result in less IO from the preference for Exadata to offload.
- The Exadata enhancement to the optimizer for offloading preference will no longer exist once migrated to Azure- this means the optimizer will be more likely to create different execution plans that have different IO.
- Without HCC, data will have to be read uncompressed unless the customer licenses for it outside of Exadata. This is one licensing push I make for a customer leaving Exadata and going to Azure from Exadata- get HCC!
cell physical IO bytes eligible for predicate offload: This is the data eligible for storage indexing and is important as we identify the amount of physical indexing that will need to be supplemented once this feature is no longer in place. Don’t skip this and think the performance will just be fine. This is akin to moving a database without 50% or more of the indexes. Not a good idea for performance.
We can even estimate the efficiency of the smart scans by performing the following from the numbers above:
Smart Scan Efficiency=100-((100/<cell physical IO bytes eligible for predicate offload>) * <cell physical IO interconnect bytes returned by smart scan>)
Using the example above with my numbers in my screenshot, we’d get the following:
100-((100/3099793357070)* 2750799353303)
Resulting in a value from our example of 88.7%
cell physical IO bytes saved by storage index: This is the amount of IO that would have increased if the storage indexes didn’t exist. If the database was simply moved to Azure without identifying the storage indexes, (columns, etc.) and recreated as physical indexes on the new hardware, this IO would have to be added to the totals and latency expected.
If the indexes will be created and if it was done the way I would as a DBA, there would be a full justification for the index to begin with-
- Is it an index to create a vertical selection of data to query from creating significant IO?
- Is there some optimization that can be done in the code or database design to eliminate the IO need/index?
- Is there a feature in Azure that will benefit and improve the IO?
No matter what, this are indexes in memory that will exist on disk in Azure and have to be added to the total IO.
cell logical write IO requests: This one can be misleading, as it also includes requests to flash cache. As flash cache has a tendency to be more used by OLTP type workloads and offloading is used by OLAP/DSS, it’s important to know the workload type and consider how the different loads may react to a migration from Exadata.
The Winners Are
Calculating IO is not going to be an exact science when migrating off of an Exadata, but there is a calculation we can use to get pretty close using an AWR report with at least a one-week window:
IO Metrics Factor= type of disk in Azure vs. the disk IO chosen for Azure, most often equals 2.5-3.5.
((Total Throughput MB/s -
((cell physical IO bytes eligible for predicate offload - cell partial write to flash cache - cell physical IO interconnect bytes + cell physical IO bytes saved by storage index)
/1024/1024))
* IO Metrics Factor) = MB Throughput to Run Oracle Database on Azure
Now keep in mind, I will have also submitted an optimization plan that will hopefully eliminate a significant amount of IO and other resource usage, but the above calculation is what I use to come up with my numbers when working with customers, at least initially.
As we’ve already discussed, Exadata is an engineered system and there are numerous features we need to take into consideration as part of the migration strategy that an impact the amount of IO necessary. Cell Nodes are just one part of this and subsequent posts will dig into those other features.
:


