
*Previously posted on the Microsoft Data Architecture Blog for the Tech Community
High IO workloads in Azure are a topic of common interest and of those workloads, Oracle Exadata tops the list. I’m going to begin to post about how the Oracle on Azure SMEs in the Cloud Architecture and Engineering team handle those.
Exadata is a unique beast- it’s not an appliance or a single database, but an engineered system. It is a collection of hardware and software intelligence designed to run Oracle workloads, especially those with high IO, efficiently. I’ve built out a high level Exadata architecture and added the main features that we need to address most when going to Azure.
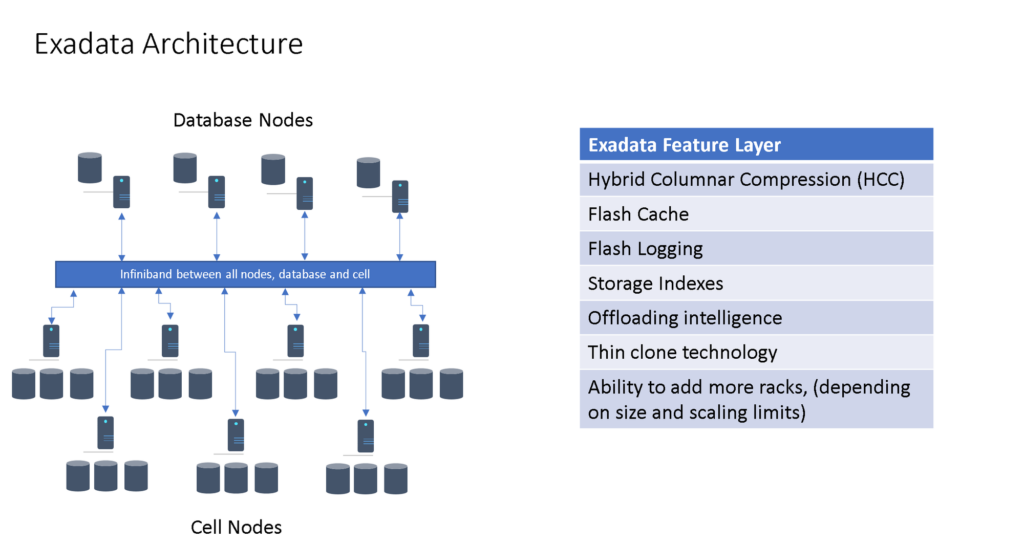
There is no way to architect an Exadata in the Azure cloud and since there are most often NUMEROUS Oracle databases running on an Exadata, it’s important to identify the workload needs for each database and then migrate the workload to the appropriately architected IaaS in Azure. Rarely do I recommend refactoring these out of the gate, as each database is a collection of schemas, that serve an individual application/function and to successfully migrate them directly off of Oracle is riddled with pitfalls. Migrating them to Azure IaaS with Oracle, then later identifying what schemas can be refactored to another platform for those customers hoping to eliminate some of their Oracle footprint is the best course of action, (in my experience.)

In the above diagram, we see the following features available on an Exadata:
- Multitenant
- In-Memory DB
- Real Application Clusters
- Active Data Guard
- Partitioning
- Advanced Compression
- Advanced Security, DB Vault
- Real Application Testing
- Advanced Analytics
- Management Packs for Oracle
- Offload SQL to Storage
- InfiniBand Fabric
- Smart Flash cache/log
- Storage Indexes
- Columnar Flash Cache
- Hybrid Columnar Compression
- IO Resource Management
- Network Resource Management
- In-memory fault tolerance
- Exafusion direct-to-wire Protocol, (This is a benefit of RAC, so put this in the RAC bucket)
With the list above, the items highlighted in Dark Red are Exadata specific. All others are Oracle specific and can be done in Azure, not just Exadata. Cross the ones that aren’t highlighted off your list as a concern. If you license for it, you can build it out and license it in Azure, too.
Oracle Real Application Clusters, (RAC) is a moot point. You can’t build it in a third-party cloud and honestly, it’s rarely something we even need. We are now architecting for the Azure cloud, (please see the blog post on HA for Oracle on Azure at the bottom of this article for more information).
That leaves us with just this to address:
- Offload SQL to Storage
- InfiniBand Fabric
- Smart Flash cache/log
- Storage Indexes
- Columnar Flash Cache
- Hybrid Columnar Compression
So, let’s step back and discuss how we identify the workloads and decide the solution on the Azure side.
Go for the Gold- AWR
Some folks like to boil the ocean- the problem is, the fish will die and there’s just no reason to do it when just trying to identify and size the workload. It’s all about what is the size of bucket it’s going to fit in. If your estimate is off by 100 IOPS/100MBPs, it doesn’t mean you’re going to mis-size the workload when you decide what sizing it falls into. It’s all about small, medium, large and extra-large architectures to begin with.
The Automatic Workload Repository, (AWR) fits this purpose and grants you valuable information about the Exadata feature use per database.
For Oracle 12.2 and above, there are significant enhancements to the AWR report that can be used to help us determine the amount of work that it will be to “decouple” from the Exadata.
For our example, we’re going to use a 4-node RAC database running on an Exadata.
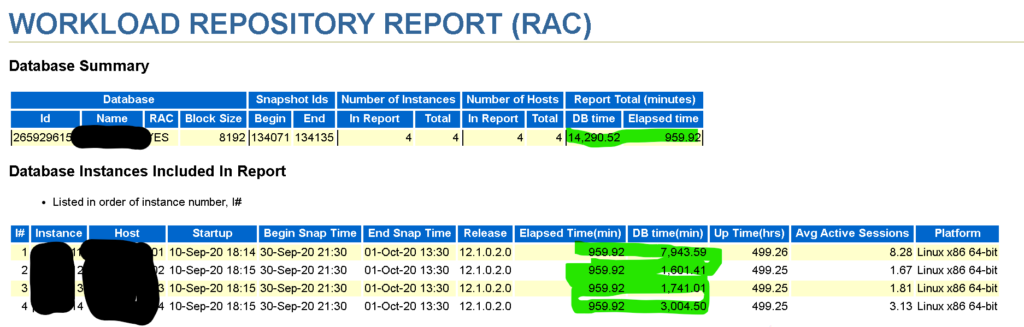
At the very top of the report, we can see the database information, the number of nodes, but even more importantly, how busy it is, comparing the elapsed time to the DB Time. Of course, we expect an OLTP is going to have higher numbers for average active sessions, where this is Exadata, and its primary bread and butter are OLAP workloads with fewer beneficial features for OLTP.
I’m not going to focus on the sizing of a database workload. You can learn how to do that in another link at the bottom of this post, but we’re going to identify the parts of the AWR report that can tell you what you’re up against to move it off of Exadata.
An AWR report is quite large and after 12.2, you will notice that Oracle [often] included the ASH, (Active Session History) and the ADDM, (Automatic Database Diagnostic Monitor) report in with the AWR. Past these two report additions to the AWR data, you will then see a section for Exadata:

In the Top IO Reasons by MB for Cell Usage, we can quickly see how each of cell nodes are being used by the database hosts for offloading:
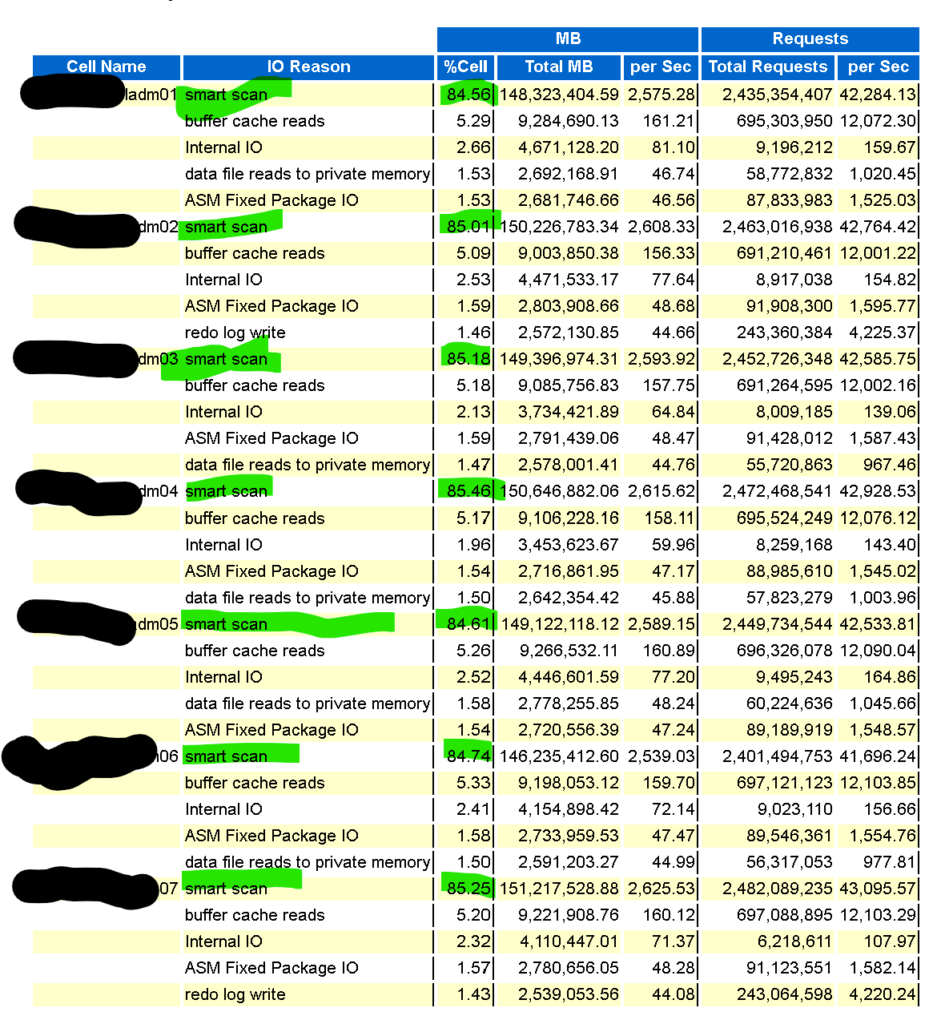
The majority of the work by the cell nodes is smart scans, i.e., offloading, and pretty consistently across the cell nodes at around 85%.
Which Database Are You Targeting?
We can then go to the next section of interest and see, broken down by database, (top ten databases, after that, the rest are just aggregated and put in under “other”) what percentage of throughput is used by each:
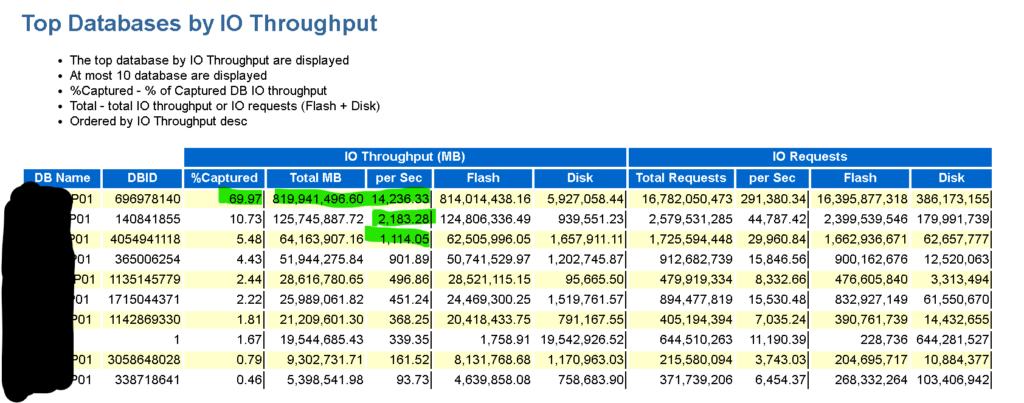
This table lists each database, and we can see, the database identified by DBID 696978140, which we’ll refer to as DB01 from this point forward, is using 70% of the total IO throughput and how much MB per second it uses on average. We don’t size by the value shown in this section, but we can easily see which database is our “whale in the pond” and most likely the reason for the Exadata investment. The next database down is less than 11%, so you can easily see the resource demand difference that the DB01 will require vs. the others.
In the section following this one, we will even see the breakdown of percentage and IOPS per database to each cell node. It often falls very close to the total you see above, with minor differences.
What Don’t You Need to Worry About?
One of the nice things about the AWR, it will also tell you when they’re NOT using a feature, such as Columnar Flash Cache:

In this post, I’ve demonstrated how to help identify the ease or challenge to migrate an Oracle database from Exadata to Azure. If you are migrating DB01, then you are going to spend more time on the IO demands for this database. If you’re moving one of the other 8 databases, (the line that appears blank is actually the ASM instance managing the storage layer) then it’s going to be a much easier time and I’d recommend aiming at one of those for a POC, not the “whale in the pond”!
For each one of the additional features in Exadata:
- Smart Flash cache/log
- Storage Indexes
- Flash Cache
- Hybrid Columnar Compression (HCC)
There is a separate section in the AWR report that corresponds to it and the databases/Exadata workloads use of it. For Hybrid Columnar Compression, it will tell you if the feature is in use and if so, then you can query the space savings and prepare for the amount of storage and the IO throughput additionally required when leaving Exadata. This commonly is the reason for us to bring in a high IO storage solution. Depending on settings for Query low, Query high, etc., the savings and performance can vary, if they need thin clones and deep compression, then I might suggest Silk to make up for the loss of those features on the Exadata.
The Kitchen Sink
Other data that comes in handy and to think about:
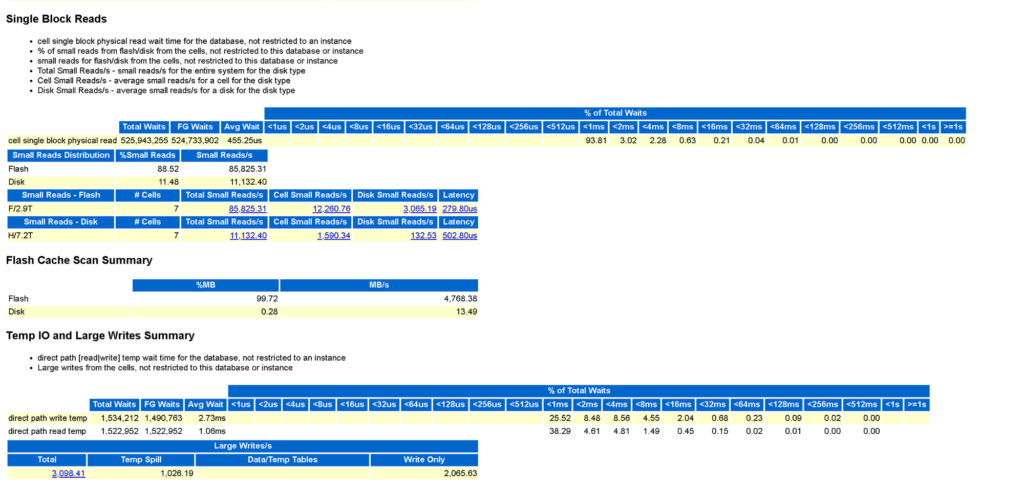
Data is provided for flash caching, and single block reads is very helpful. When you see high single block reads, it’s important to have an Oracle SME identify the database level usage of this. It often offers us insight into Oracle workloads that will BENEFIT from not being on Exadata. This is a longer discussion than what I will go in here, but it’s a less optimal use of an Exadata and worth this discussion, (another day, I promise!)
Last, but not least, is TEMP tablespace usage. Exadata can’t fix your temp problem- I’ve talked about that for years now and it’s still an issue. Temp usage is due to numerous things, but often it’s because the database is not using PGA allocation correctly from inefficient code or databases design and temp is simply disk. The faster the disk, the faster the performance, but needless to say, you’re “swapping” (best description) and performance would benefit by fitting in Process Global Area, (PGA). Slow storage will only worsen this challenge, so it’s important to know how much “swapping” to temp the database in question is doing.
In my next series in these posts, I’ll explain what options there are to deal with:
- Offloading calculations
- IO Explosion after loss of HCC
- Flash logging
- High IO Storage solutions for Exadata
- InfiniBand for network latency


