
I’m itching to dig more into the SQL Server 2016 optimizer enhancements, but I’m going to complete my comparison of indices between the two platforms before I get myself into further trouble with my favorite area of database technology.
 <–This is sooo me.
<–This is sooo me.
Index Organized Tables
Index Organized Tables, (IOT) are just another variation of a primary b-tree index, but unlike a standard table with an index simply enforcing uniqueness, the index IS the table. The data is arranged in order to improve performance and in a clustered primary key state.
This is the closest to a clustered index in SQL Server that Oracle will ever get, so it makes sense that a comparison in performance and fragmentation is the next step after I’ve performed standard index and primary key index comparisons to Oracle.
Let’s create a new copy of our Oracle objects, but this time, update to an Index Organized Table:
CREATE TABLE ora_tst_iot(
c1 NUMBER,
c2 varchar2(255),
CREATEDATE timestamp DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT pk_ora_iot PRIMARY KEY (c1))
ORGANIZATION INDEX
TABLESPACE users
PCTTHRESHOLD 20
OVERFLOW TABLESPACE users;
CREATE SEQUENCE C1_iot_SEQ START WITH 1; CREATE OR REPLACE TRIGGER C1_iot_BIR BEFORE INSERT ON ORA_TST_IOT FOR EACH ROW BEGIN SELECT C1_iot_SEQ.NEXTVAL INTO :new.C1 FROM DUAL; END; /
The PCTThreshold can be anywhere between 0-50, but I chose 20 for this example. I didn’t add any compression, as C1 is a simple sequence which won’t have the ability to take advantage of compression and I also added the additional support objects of a sequence and a trigger, just as I did for the previous test on the Oracle table.
First Data Load
Now we’ll insert the rows from ORA_INDEX_TST into ORA_TST_IOT
SQL> insert into ora_tst_iot(c2) select c2 from ora_index_tst; 995830 rows created. Elapsed: 00:00:04:01
There won’t be any fragmentation in the current table- it was directly loaded- no deletes, no updates. Although it won’t be shown in the examples, I will collect stats at regular intervals and flush the cache to ensure I’m not impacted in any of my tests.
SQL> ANALYZE INDEX PK_INDEXPS VALIDATE STRUCTURE; Index analyzed. Elapsed: 00:00:00.37 SQL> select index_name from dba_indexes 2 where table_name='ORA_TST_IOT'; INDEX_NAME ------------------------------ PK_ORA_IOT
SQL> analyze index pk_ora_iot validate structure; Index analyzed. SQL> analyze index pk_ora_iot compute statistics; Index analyzed. SQL> SELECT LF_BLKS, LF_BLK_LEN, DEL_LF_ROWS,USED_SPACE, PCT_USED FROM INDEX_STATS where NAME='PK_ORA_IOT'; 32115 7996 0 224394262 88
Well, the table IS THE INDEX. We collect stats on the table and now let’s remove some data, rebuild and then see what we can do to this IOT-
SQL> select * from ora_tst_iot 2 where c1=994830; 994830 SBTF02LYEQDFGG2522Q3N3EA2N8IV7SML1MU1IMEG2KLZA6SICGLAVGVY2XWADLZSZAHZOJI5BONDL2L 0O4638IK3JQBW7D92V2ZYQBON49NHJHZR12DM3JWJ1SVWXS76RMBBE9OTDUKRZJVLTPIBX5LWVUUO3VU VWZTXROKFWYD33R4UID7VXT2NG5ZH5IP9TDOQ8G0 10-APR-17 03.09.52.115290 PM SQL> delete from ora_tst_iot 2 where c1 >=994820 3 and c1 <=994830; 11 rows deleted. SQL> commit;
Now we see what the data originally looked like- C2 is a large column data that was consuming significant space.
What if we now disable our trigger for our sequence and reinsert the rows with smaller values for c2, rebuild and then update with larger values again?
ALTER TRIGGER C1_IOT_BIR DISABLE; INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994820, 'A'); INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994821, 'B'); INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994822, 'C'); INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994823, 'D'); INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994824, 'E'); INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994825, 'F'); INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994826, 'G'); INSERT INTO ORA_TST_IOT(C1,C2) VALUES (994827, 'H');
so on and so forth till we reach 994830…
COMMIT and then let’s rebuild our table…
Rebuild or Move
ALTER TABLE ORA_IOT_TST REBUILD;
What happens to the table, (IOT) when we’ve issued this command? It’s moving all the rows back to fill up each block up to the pct free. For an IOT, we can’t simply rebuild the index, as the index IS THE TABLE.
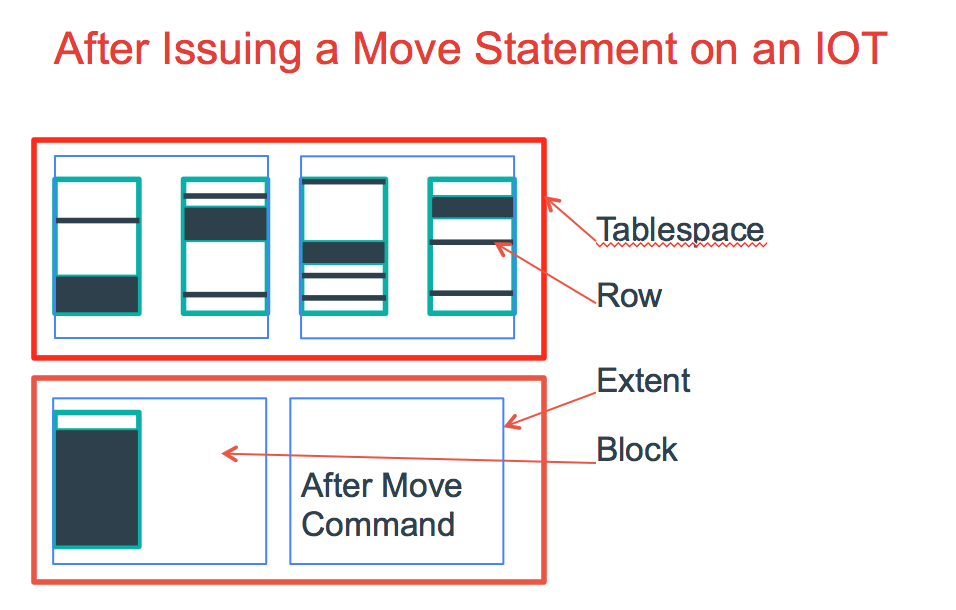
Now we’ve re-organized our IOT so the blocks are only taking up the space that it would have when it was first inserted into. So let’s see what happens now that we issue an UPDATE to those rows-
SQL> update ora_tst_iot set c2=dbms_random.string('B',200) 2 where c1 >=994820 3 and c1 <=994830; 11 rows updated.
So how vulnerable are IOTs to different storage issues?
Chained Rows
Chained Rows after updating, moving data and then updating to larger data values than the first with 10% free on each block?
Just 11 rows shows the pressure:
SQL> SELECT 'Chained or Migrated Rows = '||value FROM v$sysstat WHERE name = 'table fetch continued row'; Chained or Migrated Rows = 73730
Data Unload
Let’s delete and update more rows using DML like the following:
SQL> delete from ora_tst_iot 2 where c2 like '%300%'; 4193 rows deleted.
Insert rows for 300 with varying degree of lengths, delete more, rinse and repeat and update and delete…
So what has this done to our table as we insert, update, delete and then insert again?
SQL> SELECT table_name, iot_type, iot_name FROM USER_TABLES WHERE iot_type IS NOT NULL; 2 TABLE_NAME IOT_TYPE IOT_NAME ------------------------------ ------------ ------------------------------ SYS_IOT_OVER_88595 IOT_OVERFLOW ORA_TST_IOT ORA_TST_IOT IOT
This is where a clustered index and an IOT is very different. There is a secondary management object involved when there is overflow. If you look up at my creation, yes, I chose to create an overflow. Even if I drop the IOT properly, the overflow table will go into the recycle bin, (unless I’ve configured the database without it.)
SQL> select index_name from dba_indexes 2 where table_name='ORA_TST_IOT'; INDEX_NAME ------------------------------ PK_ORA_IOT SQL> analyze index pk_ora_iot validate structure; Index analyzed. SQL> select blocks, height, br_blks, lf_blks from index_stats; BLOCKS HEIGHT BR_BLKS LF_BLKS ---------- ---------- ---------- ---------- 32768 3 45 32115
We can see, for the blocks, the rows per leaf blocks aren’t too many- this is a new table without a lot of DML, but we still see that with the current configuration, there aren’t a lot of rows returned per leaf block.
When we select from the IOT, the index is in full use and we can see that with the proper pct free/pct used, the index is still in pretty good shape:
SQL> select * from table(dbms_xplan.display_awr('fbhfmn88tq99z')); select c1, c2, createdate from ora_tst_iot Plan hash value: 3208808379 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time PLAN_TABLE_OUTPUT ---------------------------------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 8709 (100)| | 1 | INDEX FAST FULL SCAN| PK_ORA_IOT | 995K| 206M| 8709 (1)| 00:01:4 5 | 13 rows selected.
SQL> analyze index pk_ora_iot validate structure; Index analyzed. SQL> SELECT blocks, height, br_blks, lf_blks FROM index_stats; BLOCKS HEIGHT BR_BLKS LF_BLKS ---------- ---------- ---------- ---------- 32768 3 45 32058 SQL> select pct_used from index_stats; PCT_USED ---------- 88
I Did a Bad
So now what happens, if like our original test, we shrink down the percentage of what can be used and reorganize, (and please don’t do this in production…or test….or dev….or ever! 🙂)?
SQL> alter table ora_tst_iot move pctfree 90; Table altered. SQL> analyze index pk_ora_iot validate structure; Index analyzed. SQL> SELECT blocks, height, br_blks, lf_blks FROM index_stats; BLOCKS HEIGHT BR_BLKS LF_BLKS ---------- ---------- ---------- ---------- 172928 3 228 165630
Well, that’s a few more leaf blocks, eh? Insert after enabling trigger again-
SQL> BEGIN FOR i in 1..1000000 LOOP INSERT INTO ORA_TST_IOT(c2) VALUES(i); END LOOP; COMMIT; END; /
Now we have our elapsed time for Azure inserts of 1 million records with 100% and 10%. Let’s compare it to our IOT. The IOT move command to fill the blocks to 100% was quite fast. Of course, the reverse, only allowing for 10%, (90% free) took F.O.R.E.V.E.R…, (OK, it sure felt like it…why didn’t I just truncate it? Oh, yeah, I wanted it to be a real test, not simply an easy test..)
Note: For this test, we’ll rebuild after updating the pctfree each time.
10% Fill Factor in SQL Server and 1 million insert: Elapsed time: 23 minutes, 18 seconds
90% PCTFree in Oracle and 1 million insert: 7 min, 12 seconds
100% Fill Factor in SQL Server and 1 million insert: Elapsed Time: 4 minutes, 43 seconds
0% PCTFree in Oracle and 1 million insert: 1 min, 8 seconds
REBUILD of the Oracle IOT to make it 90% free in each block? Elapsed Time: 8 hrs, 21 minutes, 12 seconds
…along with four backups of archive logs it generated that filled up the archive dest… 🙂 Now the AWS Trial is to be used to test out the Delphix product, not to test out index performance in a high insert/delete/update scenario, so I’ve been asking for some of these challenges, but it was still a great way to build this out quickly and then compare.
Results
In this test, this was the overall results:
- Less overhead during transactional processing when it comes to inserts, updates and deletes to the IOT.
- Improved performance on any selects that require the data to be sorted in sequential order.
- Similar performance to SQL Server clustered indexes on complex queries and less sort temp usage.
- Limited use case than SQL Server clustered indexes, as these are quite common and IOTs are less used in the Oracle space.
- More maintenance upkeep as we will need to reorganize the IOT if its used with processing that includes a lot of inserts, updates and deletes.
- DBCC rebuilds of a clustered index uses less resources and doesn’t impact the transaction log as it does Oracle’s rollback and archive log. It was easier to build the table with a high pct free storage configuration and then do an insert of the data, then drop the old table than to do an “alter move” command.
Now there’s more to do comparisons on, so I’m going to dig in more on the SQL Server side, but here’s to Oracle Index Organized Tables, (IOTs)!


