
*Previously posted on the Microsoft Tech community Data Architecture Blog
IaaS (INFRASTRUCTURE AS A SERVICE) Cost Optimization for RDBMS (Relational Database Management Systems) workloads is a common request. One of the challenges is that many want to just hand this type of task over to infrastructure and call it good. The problem is that when making changes to VM (VIRTUAL MACHINES) series, memory, storage, and configuration on the physical VM, the database, no matter what platform, can adjust to work intelligently with what has been given in hardware resources. Yes, some RDBMS may be more adaptable than others with changes to infrastructure, but you should assume that having a database specialist as part of the optimization can save from confusing changes in performance that have nothing to do with the infrastructure and all because the relational system that resides on it.
Change is the The Constant
The idea that the database workload will not change after changing the VM or resources for memory and storage is akin to taking a ten-year old child and expecting him to behave the same no matter if you have put him in clothes to fit a five-year old or a fifteen-year-old.
Think about it- if you have no room to move, you might behave a bit differently than if you have just enough room or if you have a ton of extra room. Databases are not much different. If IO is limited, a query may choose to perform a row-by-row path to reach an answer vs. if IO is not limited, where fast scan of an objects to create an object in memory that fulfills the results.
Know The Baseline
It is rarely this simple when reviewing the data from a cost optimization exercise, but I can leave you with some clear recommended practices for what to gather while performing a cost optimization exercise in IaaS:
- Ensure you are using the right tool for the database platform in question-
- Oracle- AWR (Automated Workload Repository) and ASH (Active Session History).
- SQL Server/Azure SQL- DMVs (Dynamic Management Views), Query Store and Profiler.
- PostgreSQL -PGfouine, PG-badger, auto-explain, PS Explain Visualizer
- DB2 -DB2 Performance Analyzer
- Have a baseline of performance data that you can compare to. If you do not know what you are comparing it to, then you are making assumptions. That is not a good place for any database administrator to be.
- After each workload run, inspect the data for the top ten processes to see if there is any variation in the execution times. If variations are discovered, then take a deeper look, even if the total execution time is in line with the baseline. Ignoring this could allow you to miss a breakthrough that was hidden by a performance hit that could have been addressed, allowing for the other benefits to come through.
- If there is a significant increase in elapsed time, review the elapsed time for the top ten again. Verify that there is not an outlier now present that is not in the baseline. For workload tests that even take hours, a single query performing in an erratic way can throw an execution test out the window.
Seeing is Believing
An example of this can be viewed in the following example. The execution time had increased significantly from the baseline used and on review of the infrastructure and times, resulted in the CSA (CLOUD SOLUTION ARCHITECT) thinking the change to the VM series for the test had been a failure.
Here is our baseline we were targeting for top SQL, (Using an Oracle database and AWR report):
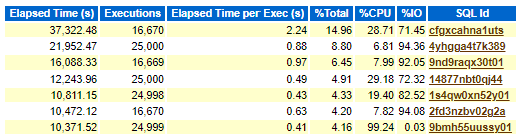
For our run after the baseline was clearly degraded with the infrastructure changes, but where the degradation was first blamed on the infrastructure, note the difference on the section for Top SQL by Elapsed Time:
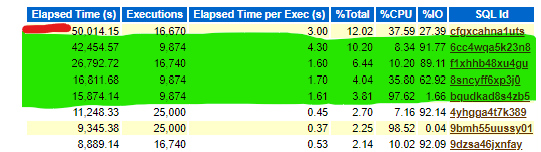
Now those SQL IDs highlighted in green weren’t present in the baseline and should be an indicator that something has changed inside the database, not the storage or VM. If a change had happened at the VM, we’d expect to see changes in statements which consume memory and vCPU. If it was a storage issue, we could see some memory changes and definitely IO performance impacts to ALL SQL IDs, but instead we are seeing just four SQL IDs involved.
I want to point out- you will notice these are the same workloads by the number of executions, but we have those four new SQL IDs in the top SQL. There is higher elapsed time for the #1 SQL ID, but at the same time, the IO has decreased extensively with the change that was made, so again, we know it’s not an infrastructure problem. The three bottom SQL IDs are performing significantly better, so the overall execution time for the jobs that the Infrastructure CSA is privy to is misleading to what is really going on. Think about how frustrating this is when we only have half the picture that explains what is going on and the performance data we are provided as DBAs can offer incredible insight.
What Happened
In this example, the storage change caused the Oracle optimizer to choose a different plan for a number of statements, which could be viewed with an AWR SQL ID specific report, (awrsqrpt.sql) and compared to the baseline snapshots. This helped us realize that we quickly had to lock down this change and rerun the test to identify if there was a performance benefit that we were missing without the database behavior change being taken into consideration.
Once this change was reversed, (the nightly space advisor and adaptive plans had created the situation, when consistency is a crucial factor in a controlled situation such as a cost optimization exercise) the benefit could be seen and the increase to the #1 SQL ID was reversed, too:
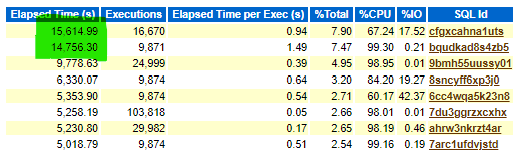
We can also look at the elapsed time per execution to see how it has decreased with the optimization of the VM and storage options. Any SQL ID shown with a value of n/a was due to the SQL falling out of the total 97% of SQL execution time:
| SQL ID | Baseline | 1st Run | 2nd Run |
| cfgxcahna1uts | 2.24 | 3.00 | .94 |
| 4yhgga4t7k389 | .88 | .45 | .08 |
| 9nd9raqx30t01 | .97 | .49 | n/a |
| 14877nbt0gj44 | .49 | .29 | .14 |
| 1s4qw0xn52y01 | .43 | .18 | n/a |
| 2fd3nzbv02g2a | .63 | .33 | n/a |
| 9bmh55uussy01 | .41 | .37 | .39 |
Of the top SQL in the baseline, all decreased in subsequent runs except the final one, which makes it quite possible to address if requested by the customer. We can see the overall elapsed time has decreased for the workload run outside of the outlying, four offenders.
What about the four offending statements that suffered after the adaptive plans and space advisor had impacted it?


