*Previously posted on the Microsoft Data Architecture Blog for the Microsoft Tech Community.
One of the best allocations of an Oracle SME specialist at Microsoft is when there is a complex data/infra issue for one of our customers. We have a unique set of skills, understanding relational workloads along with deep infrastructure knowledge combined to identify issues that may be missed without these skills.
For one customer this last week, they were receiving poor IO performance on one of their Oracle databases running on a VM in Azure. It’s quite easy to just blame storage or scale up the VM, but that not only costs money, it doesn’t get to the real culprit, which so often has nothing to do with the Azure cloud, but lack of understanding of the inter-dependency between database and infrastructure.
Collect the Information
For this type of troubleshooting, there are two things required:
- Information about the specific Azure VM SKU and the storage/storage configuration the database is running on.
- And Automatic Workload Repository, (AWR) report from the window the performance problem was experienced. As AWR reports are by default, 1-hour snapshots, a manual snapshot can be issued for the beginning and ending snapshot to isolate the performance window.
Armed with this information, we can then start to gather a picture of what has occurred-
The VM SKU the database is running on is important for us to attain detailed information about what resources are available and what limits are set:

Each of the VM series have their own category links and spend the time to understand the differences between storage that’s been configured to take advantage of host level caching vs. uncached and network attached storage. For our customers, the limits highlighted in yellow are what they are held to.
This VM is a good fit for the customer. It has 64vCPU and if they use host level caching, they can get upwards of 4000MBPs. This was part of the problem though. I was sent the storage used for the Linux VM:
No host level read-only caching turned on for any of the P30 disks that could take advantage of it.
There was more than just demonstrated here, but the important thing to know is that the OS was on a premium SSD P10 disk, (good) and then the rest of the data was residing on P30 disks and one P70 disk.
Optimize the Storage
I know that most would say, “Go Ultra SSD” but just ignore Ultra disk unless you have redo latency and then Ultra SSD has a use case for redo logs, but for most, large Oracle databases, Ultra is an expensive choice that is still limited to the max uncached IO for the VM chosen. In this case, that means no matter if you use Premium SSD or Ultra SSD, you can only get a max of 1735 MBPs WITHOUT caching. For our customer, they had the P30s and a P70… If we view this data in a different way, I think it might help understand the reason I want a slightly different choice in disk:
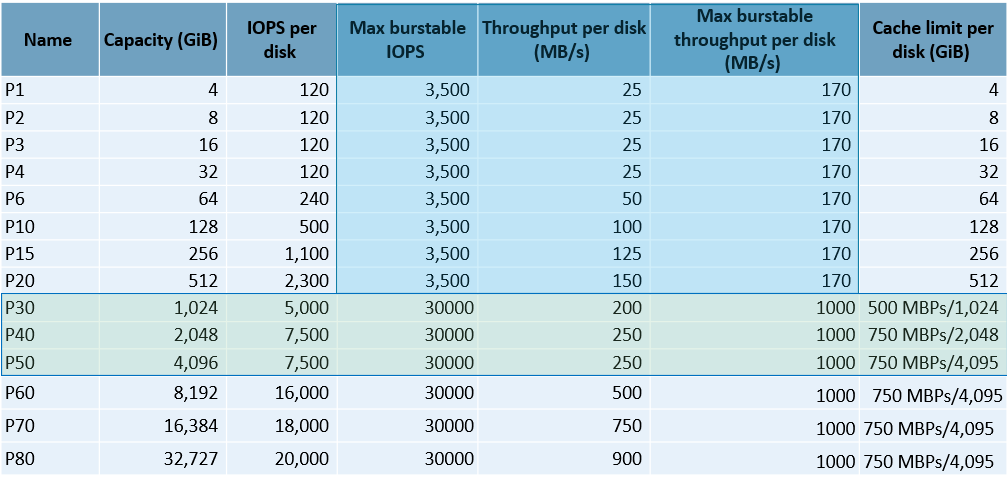
We talk a lot about bursting, but relational workloads need a consistent, high performant storage solution. With premium SSD, we have something called read-only host-level caching. In the last column for the P30-P50 disks, you may realize that this caching option offers us a free boost in performance for high read workloads, which is something we see often with Oracle. Yes, customers could pay for bursting, and although we’re satisfied with it when testing, bursting has to be available and we find in reality that most workloads in the cloud need bursting at the same time, so it results in inconsistent performance for Oracle. Cached read-only workloads do fantastic and if you are deploying multiple P30, (1TB) disks and having IO problems, why wouldn’t you go to P40s for half the number of disks and get 250MBPs more throughput with a free feature you can turn on?
The reason the customer was using the P70 was to get the throughput, but actually didn’t need all the storage, so when shown they could get 750MBPs with the smaller, 2TB, P40 disks, this made great economic sense, too.
First step:
- Replace the P30 and P70 disks with P40 Premium SSD.
- Turn on read-only host-level caching on each P40 disk.
Optimize the Database to Work with the Infrastructure
Now that we’ve identified what is needed for the storage, we need to identify anything in the database that may be contributing to the issues and the AWR quickly shows we do have a problem:
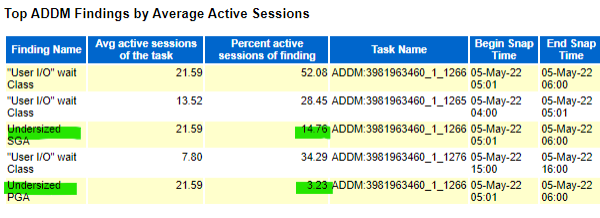
It might be easy to say, “We fixed the storage, so those User IO problems will go away.” But we really need to understand what is causing it and although the undersized System Global Area, (SGA) is also something we may want to investigate; the undersized Process Global Area, (PGA) is more important. The SGA and PGA are the two memory areas used by Oracle databases. For this situation, we have to ask, “What happens when we don’t have enough PGA to allocate to a given process in Oracle?”

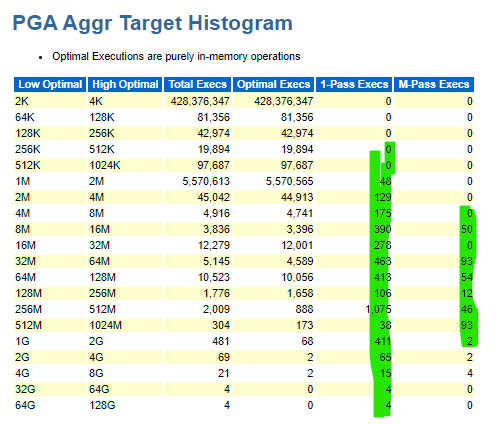
The PGA varied drastically during the window when performance degraded, yet was it enough? The Foreground wait events quickly lets us know what happens when there isn’t enough PGA to perform sorts, hashes, etc. in memory:
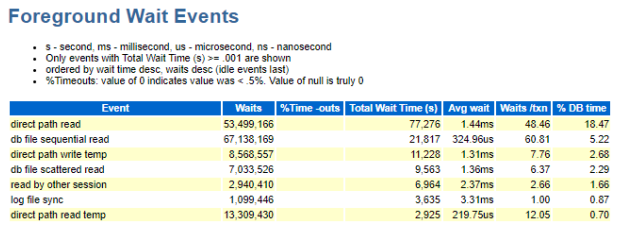
That sorting and hashing must run in temp and the temp tablespace is IO. We can see how many times the PGA had to “swap” to temp, along with how much disk had to be used to perform the task in the AWR report: